Papers·1개월 전
DeScore: 비디오 보상 모델의 추론과 점수를 분리한 'think-then-score' 패러다임
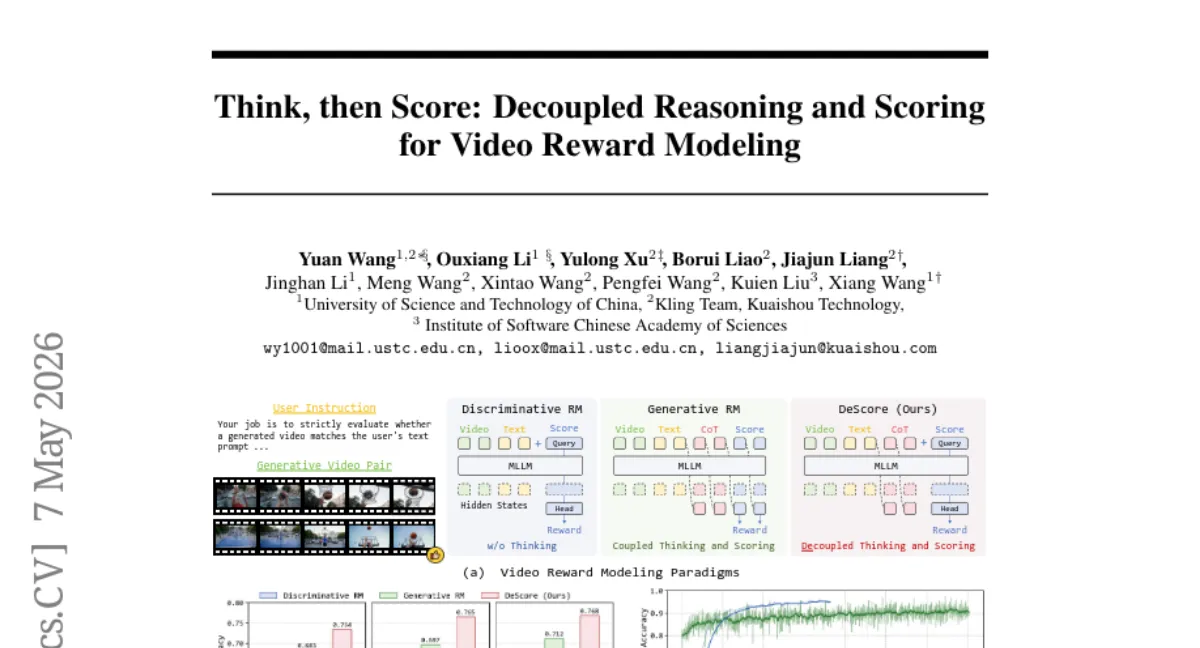
DeScore는 비디오 보상 모델의 일반화 성능을 높이기 위해 추론(CoT)과 점수를 분리한 'think-then-score' 방식을 제안합니다. MLLM이 먼저 CoT를 생성하고, 이후 별도의 판별적 점수 모듈이 최종 보상을 예측하는 구조로, 기존 생성형 RM의 최적화 병목을 해결했습니다. 두 단계 학습(판별적 콜드 스타트 + 이중 목표 강화학습)을 통해 CoT 품질과 보상 정확도를 독립적으로 개선하며, 다양한 비디오 태스크에서 기존 방법 대비 우수한 일반화를 보였습니다. 단, 학습에 MLLM 파인튜닝이 필요해 계산 비용이 크다는 점은 한계입니다.
- #reward-model
- #video-generation
- #chain-of-thought
- #mllm
- #huggingface
Yuan Wang