News·1개월 전
Triton 커스텀 커널로 JumpReLU SAE 추론 2배 가속
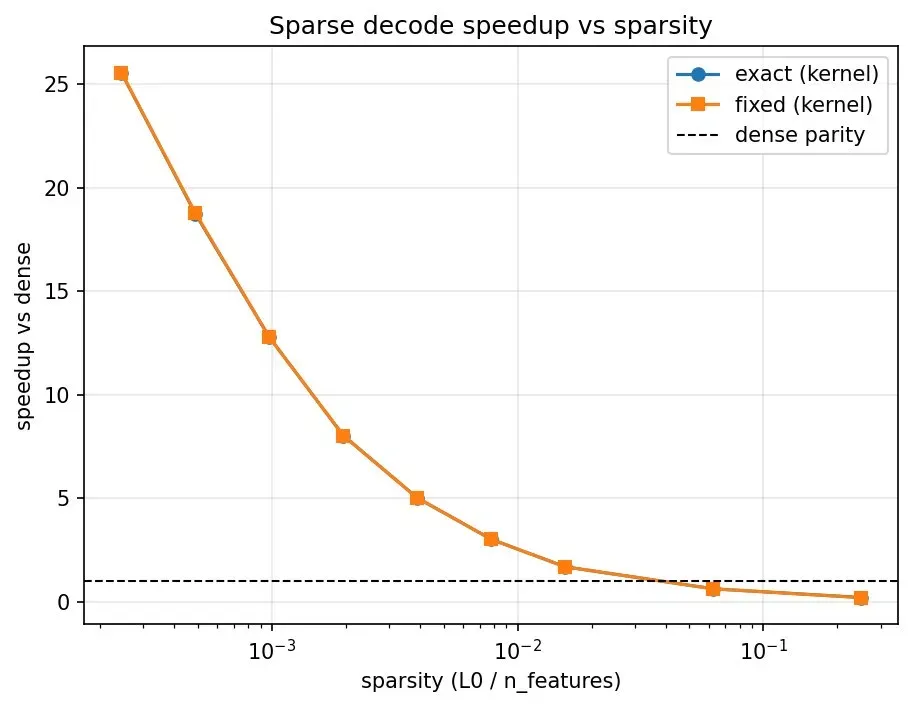
LessWrong 게시글에서 JumpReLU Sparse Autoencoder의 추론 효율을 개선하는 방법을 소개했습니다. DeepMind가 제안한 JumpReLU는 기존 ReLU 대신 학습된 임계값 아래 활성화를 0으로 만드는데, Triton 커스텀 커널을 작성해 연산을 통합함으로써 PyTorch 구현 대비 최대 2배 속도 향상을 달성했습니다. 이는 대규모 해석 가능성 연구에서 SAE 추론 병목을 줄이는 실용적 접근입니다.
JumpReLU SAE의 추론 속도를 Triton 커스텀 커널로 개선한 사례입니다.
골자
- 대상 — JumpReLU Sparse Autoencoder — DeepMind가 제안한 방식으로, ReLU 대신 학습된 임계값으로 sparse feature를 추출합니다.
- 방법 — PyTorch의 element-wise 연산을 Triton 커스텀 커널 하나로 통합해 메모리 접근과 커널 런칭 오버헤드를 줄였습니다.
- 성능 — 실험 결과, 기존 PyTorch 구현 대비 최대 2배 추론 속도 향상을 확인했습니다.
배경·맥락
- SAE는 모델 내부 활성화를 sparse feature로 분해하는 해석 가능성 도구로, 대규모 연구에서는 추론 비용이 병목이 됩니다.
- 기존 한계 — JumpReLU는 thresholding, masking 등 여러 step으로 구성돼 PyTorch에서 각각 별도 커널로 실행됩니다.
자금 용처·향후
- 적용 — 코드는 공개되어 있으며, 기존 SAE 파이프라인에 쉽게 통합할 수 있습니다.
- 확장 — 동일한 최적화 기법을 다른 SAE 변형(Gated SAE 등)에도 적용 가능할 것으로 보입니다.
편집자 한 줄
Triton 커스텀 커널로 2배 가속은 단순하지만 실용적인 최적화로, 해석 가능성 연구의 스케일링 병목을 낮추는 데 기여할 만합니다.
- #jumprelu
- #sae
- #triton
- #inference-optimization
- #mechanistic-interpretability
LessWrong