Papers·1개월 전
Kling 팀, VLM을 '선생님'으로 활용한 비디오 추론 — VBVR-Bench·RULER-Bench 평균 16.7점 향상
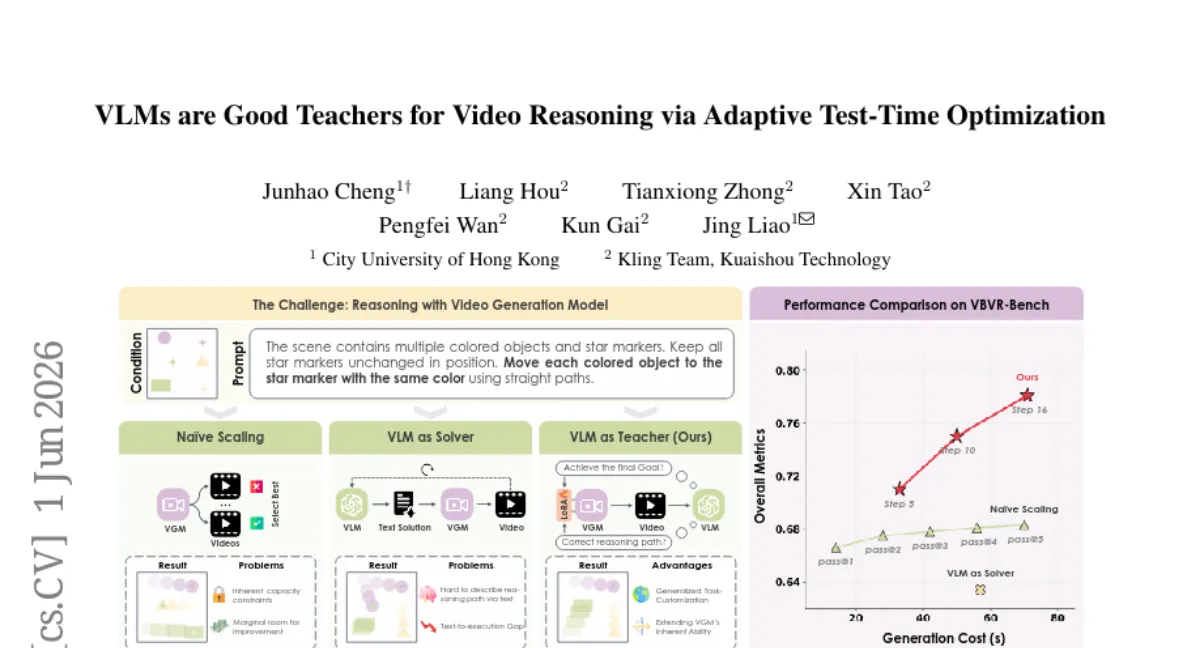
Kling 팀이 비디오 생성 모델(VGM)의 추론 능력을 향상시키기 위해 VLM을 '선생님'으로 활용하는 패러다임을 제안했습니다. VLM이 태스크 규칙을 추출해 미분 가능한 보상 함수를 만들고, 테스트 시점에 VGM의 LoRA 모듈을 최적화하여 가이드합니다. 기존 VLM-as-Solver 대비 16.3점, Best-of-N 대비 14.5점 높은 성능을 보였지만, 테스트 시 추가 연산이 필요하다는 한계가 있습니다.
Kling 팀이 VLM을 '선생님'으로 삼아 비디오 생성 모델의 추론을 개선하는 방법을 공개했습니다.
핵심 결론
- 벤치마크 — VBVR-Bench와 RULER-Bench에서 평균 16.7점 향상, 기존 VLM-as-Solver(+0.4점)와 Best-of-N(+2.2점)을 큰 폭으로 앞질렀습니다.
- 비용 — 테스트 시 추가 연산이 들지만, 같은 비용 대비 Best-of-N보다 14.5점 높은 효율을 보였습니다.
방법
- VLM 역할 전환 — VLM을 문제 해결사(solver)가 아닌 선생님(teacher)으로 사용합니다. VLM이 태스크 규칙을 추출해 미분 가능한 보상 함수를 만듭니다.
- 테스트 시 최적화 — VGM Reasoner의 LoRA 모듈을 테스트 시점에 온라인 최적화하여, VGM의 본래 추론 범위를 넘어서는 적응을 가능하게 합니다.
- 텍스트 설명 대신 보상 신호로 가이드하므로, 미세한 시공간 디테일을 더 잘 전달할 수 있다는 점이 특징입니다.
한계·조건
- 연산량 — 테스트 시 LoRA 최적화가 추가로 들어가므로, 실시간 추론에는 아직 무리가 있습니다.
- 일반화 — 평가된 벤치마크는 특정 태스크(기호·일반 추론)에 국한되어, 더 다양한 도메인에서의 검증이 필요합니다.
- 코드 — 프로젝트 페이지는 공개되었으나, 코드와 모델 가중치는 아직 공개되지 않았습니다.
편집자 한 줄
VLM을 단순한 solver 대신 teacher로 쓰는 발상 전환이 인상적입니다. 다만 테스트 시 최적화 비용이 어느 정도인지 구체적인 수치가 나오면 더 좋겠네요.
- #video-reasoning
- #vlm
- #vgm
- #lora
- #kling
Kling Team