News·1개월 전
GPT-5.5, CoT 없이 인간 3분짜리 과제 50% 정확도 — METR 연구
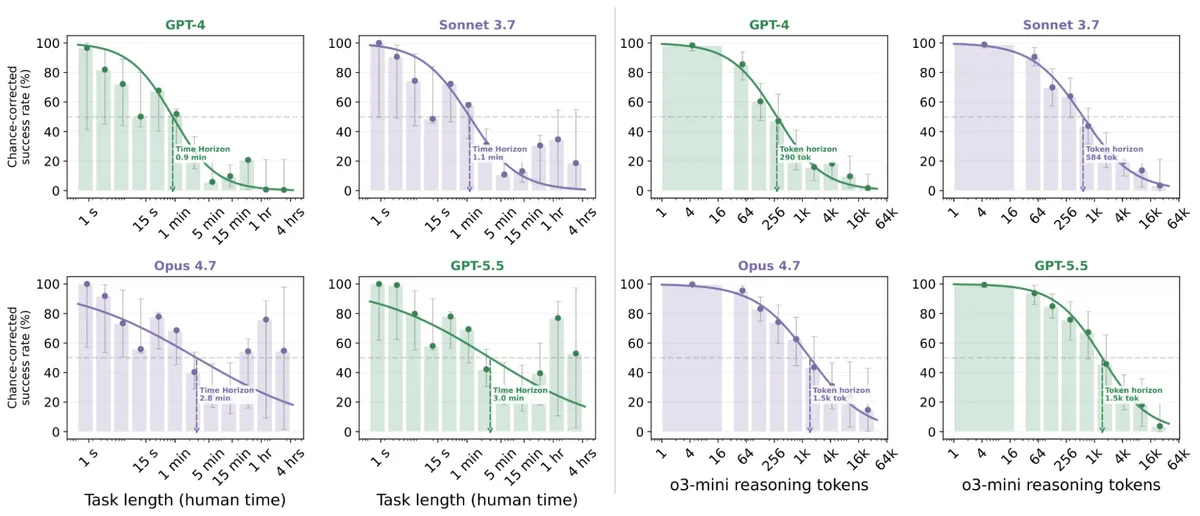
METR 연구에 따르면, 프론티어 모델이 chain-of-thought(CoT) 없이 완료할 수 있는 과제의 시간 지평이 2019년 이후 매년 약 2배씩 증가했습니다. GPT-5.5는 인간이 평균 3분 걸리는 과제를 CoT 없이 50% 성공률로 수행합니다. CoT 없이 추론하는 능력은 안전성 모니터링과 정렬에 중요한 함의를 가집니다.
METR이 프론티어 모델의 CoT 없는 추론 능력을 측정한 결과, 시간 지평이 매년 두 배씩 증가하고 있습니다.
골자
- 측정 대상 — GPT-2(2019)부터 GPT-5.5(2026)까지 14개 프론티어 모델을 43개 벤치마크(수학·코딩·지식·에이전트 도구·안전)로 평가했습니다.
- 핵심 수치 — GPT-5.5는 CoT 없이 인간 3분짜리 과제를 50% 성공률로 수행합니다. 이 시간 지평은 2019년 이후 매년 약 2배씩 증가했습니다.
- 비교 — CoT가 있는 경우(METR 기존 연구) 시간 지평이 CoT 없는 경우보다 약 2배 빠르게 증가 중입니다. GPT-4 이후 격차가 벌어졌습니다.
배경·맥락
- 1년 전 METR은 모델이 CoT와 함께 완료할 수 있는 과제 길이가 수개월마다 두 배가 된다고 보고했습니다.
- 안전성 함의 — CoT 없이도 추론할 수 있다면, 배포 시 모니터링이 모델의 의도와 계획을 파악하기 어려워집니다. 또한 인간 사고 패턴과의 괴리가 커질 수 있습니다.
- 저렴한 평가 — 이 테스트는 추론 컴퓨트를 많이 필요로 하지 않아 비용 효율적으로 실행 가능합니다.
자금 용처·향후
- 제안 — METR은 AI 기업들이 no-CoT 시간 지평을 공식적으로 추적할 것을 권장합니다. 이는 모델이 CoT 모니터 없이 얼마나 추론할 수 있는지 하한을 제공합니다.
편집자 한 줄
CoT 없는 추론 능력의 증가는 정렬 연구에 새로운 과제를 던집니다. 모니터링이 무력화될 가능성을 고려한 대비가 필요해 보입니다.
- #metr
- #cot
- #gpt-5.5
- #ai-safety
- #evaluation
LessWrong