Papers·1개월 전
SpatialClaw: VLM에 코드 실행 인터페이스로 3D/4D 공간 추론 성능 +11.2p 개선
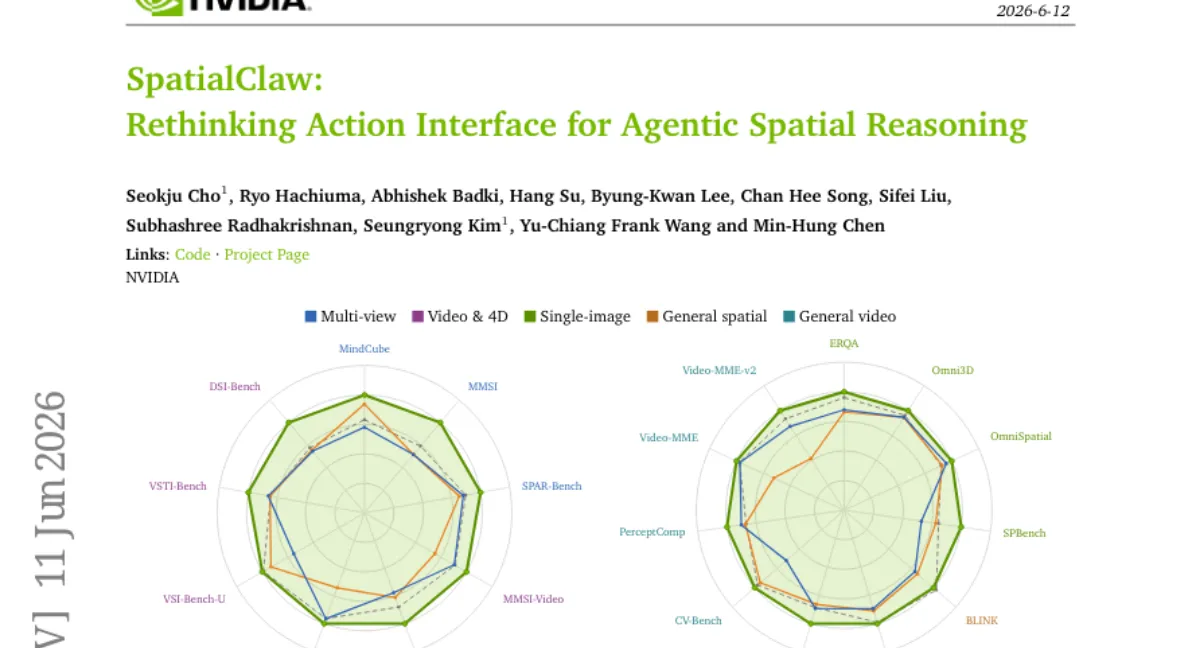
NVIDIA 연구팀이 VLM(비전-언어 모델)에 코드를 실행 인터페이스로 제공하는 훈련 없는 프레임워크 SpatialClaw를 제안했습니다. 기존 단일 패스 코드 실행이나 구조화된 도구 호출 방식의 유연성 부족을 해결하기 위해, 상태 저장 Python 커널을 유지하며 각 단계마다 이전 출력을 참조해 코드 셀을 실행합니다. 20개 3D/4D 공간 추론 벤치마크에서 평균 59.9% 정확도로 최근 spatial agent 대비 +11.2p 향상, 6개 VLM 백본에서 일관된 개선을 보였습니다.
NVIDIA 팀이 VLM의 3D/4D 공간 추론을 위해 코드를 실행 인터페이스로 사용하는 훈련 없는 프레임워크 SpatialClaw를 공개했습니다.
핵심 결론
- 벤치 — 20개 정적/동적 3D/4D 공간 추론 태스크에서 평균 59.9% 정확도, 기존 spatial agent 대비 +11.2p.
- 일관성 — 6개 VLM 백본(GPT-4o, Qwen2-VL 등)에서 모델·벤치별 튜닝 없이도 일관된 개선.
방법
- 코드 인터페이스 — VLM이 각 단계마다 Python 코드 셀을 생성·실행하며, 이전 출력(텍스트/시각)을 조건으로 분석 전략을 동적으로 조정.
- 상태 저장 — 입력 프레임과 지각·기하학 기본 요소가 미리 로드된 Python 커널을 유지해 중간 결과를 자유롭게 조합.
- 기존 단일 패스 코드 실행이나 고정된 도구 호출보다 유연하며, 복잡한 3D/4D 추론에 적합합니다.
한계·조건
- 훈련 불필요 — SpatialClaw는 훈련 없이 VLM을 그대로 사용하므로 추가 학습 비용이 없습니다.
- 코드 공개 — 논문에서 코드 공개 여부는 명시되지 않았습니다.
- 벤치마크가 다양하나, 실제 로봇이나 실시간 환경에서의 평가는 포함되지 않았습니다.
편집자 한 줄
코드 실행 인터페이스가 VLM의 공간 추론을 얼마나 확장할 수 있는지 보여주는 흥미로운 접근입니다. 다만 실제 배포 시 코드 실행 안정성과 지연 시간이 추가 과제가 될 수 있겠네요.
- #spatial-reasoning
- #vlm
- #code-as-action
- #nvidia
NVIDIA