News·1개월 전
k-스파스 오토인코더, 소형 추론 모델의 사고 패턴 포착 가능
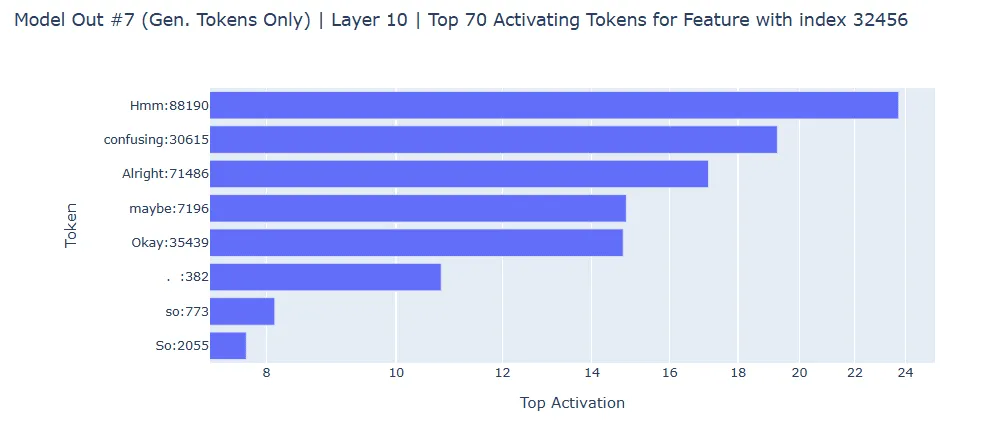
k-스파스 오토인코더로 DeepSeek R1 Distill Qwen 1.5B 모델에서 추론 과정에 특화된 특징을 추출했습니다. 레이어 10의 특징 32456, 6252, 31146 등이 추론 관련 토큰에 강하게 활성화되었습니다. 일부 특징은 여러 토큰에 반응해 해석이 어렵지만, 특정 토큰에 선택적으로 반응하는 특징도 발견되었습니다.
k-스파스 오토인코더가 소형 추론 모델의 사고 과정을 반영하는 특징을 찾아낼 수 있을까? 실험 결과 가능성을 확인했습니다.
골자
- 모델 — DeepSeek R1 Distill Qwen 1.5B에 k-스파스 오토인코더를 훈련했습니다.
- 결과 — 추론 과정과 관련된 여러 특징이 발견되었으며, 레이어 10에서 특히 두드러졌습니다.
- 특징 — 일부는 여러 토큰에 반응해 해석이 까다롭지만, 특정 토큰에만 반응하는 선택적 특징도 존재합니다.
배경·맥락
- 스파스 오토인코더는 LLM의 해석 가능한 특징을 추출하는 데 효과적이지만, 소형 추론 모델에 대한 적용은 충분히 연구되지 않았습니다.
- 이 연구는 추론 모델이 내부적으로 사고 과정을 나타내는 특징을 가질지에 대한 질문에서 출발했습니다.
자금 용처·향후
- 한계 — 결과는 유망하나, 특징의 해석 가능성과 일반화에 추가 검증이 필요합니다.
- 다음 — 더 큰 모델이나 다양한 추론 태스크에서의 실험이 뒤따를 것으로 보입니다.
편집자 한 줄
소형 모델에서도 추론 관련 특징이 포착된 점은 흥미롭습니다. 해석 가능성 연구가 실제 모델 동작 이해에 기여할 수 있을지 지켜볼 만합니다.
- #sparse-autoencoders
- #interpretability
- #reasoning-models
- #deepseek
LessWrong