Papers·1개월 전
분포 인식 RL로 MLLM 장꼬리 회귀 성능 개선 — CCC 보상 기반 Group Relative Policy Optimization
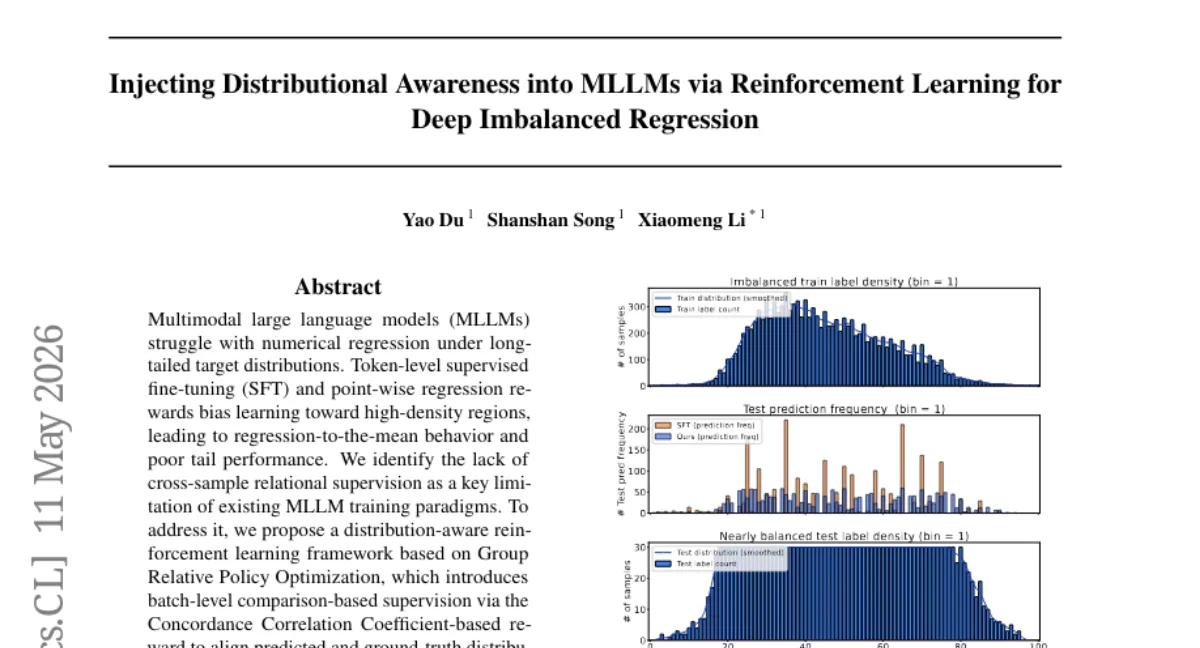
MLLM이 장꼬리 분포를 가진 수치 회귀 태스크에서 평균 회귀 편향을 보이는 문제를 해결하기 위해, batch 수준의 비교 기반 학습을 도입한 분포 인식 강화학습 프레임워크를 제안했습니다. Concordance Correlation Coefficient 기반 보상을 통해 예측 분포와 실제 분포의 상관·스케일·평균을 정렬하며, 중간·소수 샷 영역에서 특히 큰 개선을 보였습니다. 아키텍처 수정이 필요 없는 플러그-앤-플레이 방식이지만, 실험은 통합 장꼬리 회귀 벤치마크에 국한되어 있습니다.
- #mllm
- #regression
- #reinforcement-learning
- #long-tail
- #huggingface
Yao Du