Papers·어제
HDS: 강화학습으로 데이터 혼합을 최적화한 LLM 사전학습 스케줄러 — The Pile perplexity 도달 44% 적은 iteration
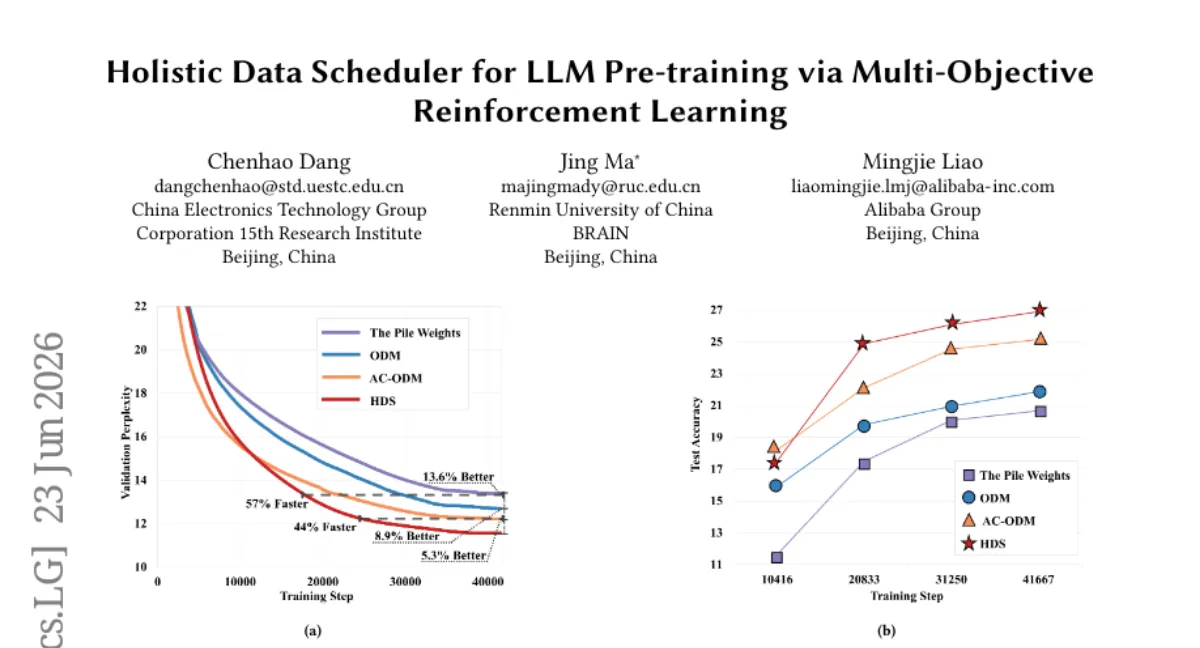
OpenDataLab 연구팀이 LLM 사전학습에서 데이터 혼합을 동적으로 조정하는 Holistic Data Scheduler (HDS)를 제안했습니다. 기존 단일 관점의 최적화를 넘어, 데이터 품질, 도메인 간 영향, 모델 가중치 규범 등 세 가지 보상 함수를 통합한 강화학습(SAC) 기반 프레임워크로, The Pile 벤치마크에서 다음 최고 방법 대비 44% 적은 학습 반복으로 동일 perplexity에 도달하고 MMLU 0-shot에서 7.2% 향상을 보였습니다. 다만 1B 이상 모델에서의 실험 결과가 추가로 필요해 보입니다.
OpenDataLab이 LLM 사전학습 중 데이터 구성을 강화학습으로 최적화하는 Holistic Data Scheduler (HDS)를 공개했습니다.
핵심 결론
- 효율 — The Pile에서 다음 최고 방법 대비 44% 적은 학습 반복으로 동일 perplexity 달성.
- 성능 — MMLU 0-shot 7.2% 향상, 다른 벤치마크에서도 일관된 개선.
방법
- 강화학습 — 데이터 스케줄링을 연속 제어 공간의 RL 문제로 정식화, SAC 알고리즘 사용.
- 다중 보상 — 데이터 기반(품질), 손실 기반(도메인 간 영향), 모델 기반(가중치 규범) 세 가지 보상을 통합한 holistic reward function 설계.
한계·조건
- 스케일 — 실험은 주로 1B 이하 모델에서 수행, 더 큰 모델에서의 검증이 필요합니다.
- 복잡도 — SAC 기반이라 학습 중 추가 연산 비용이 발생, 실제 사전학습 파이프라인에 통합 시 오버헤드 고려가 필요합니다.
편집자 한 줄
데이터 혼합을 RL로 최적화한 접근은 참신하지만, 큰 모델에서의 효과와 실제 학습 시간 단축 여부는 추가 실험을 지켜봐야 할 것 같습니다.
- #llm
- #pretraining
- #data-mixing
- #reinforcement-learning
- #opendatalab
OpenDataLab