Papers·1개월 전
UniDDT: Noisy ViT 인코더로 이해와 생성을 통합한 멀티모달 모델 — GenEval 0.87, MME 1699.5
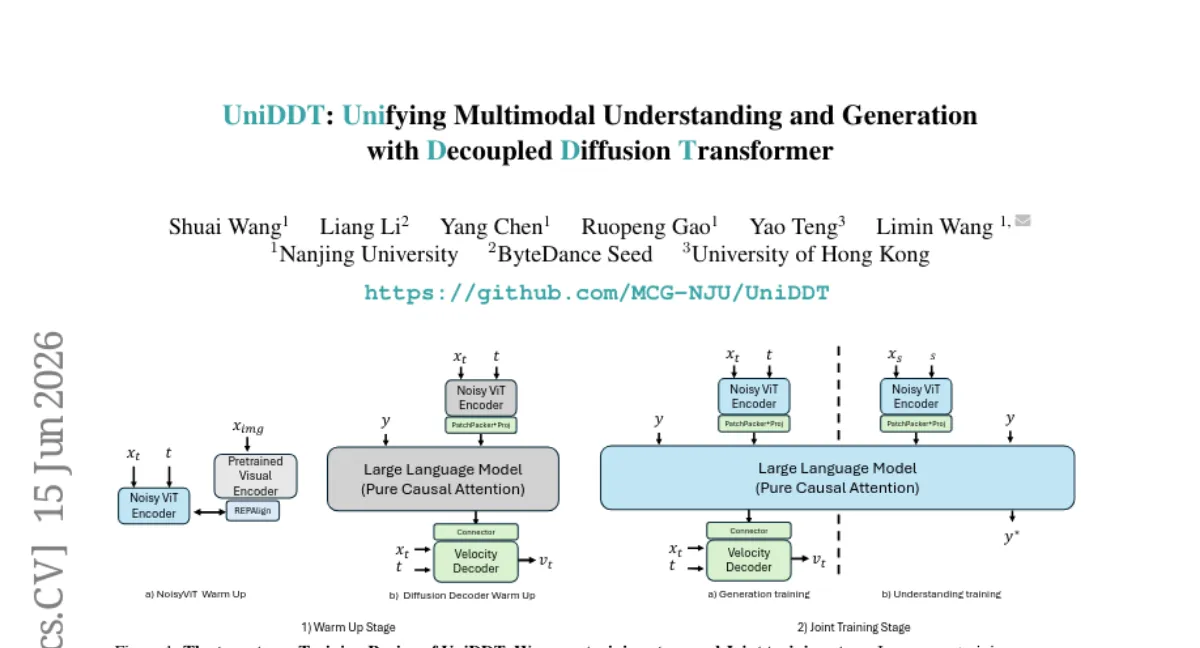
Nanjing University 팀이 멀티모달 이해와 생성을 하나의 프레임워크로 통합한 UniDDT를 제안했습니다. Noisy ViT 인코더로 잠재 공간을 통합 표현으로 활용하고, 별도의 diffusion 디코더로 텍스트 디코딩과 분리하여 이해-생성 간 학습 충돌을 완화했습니다. 동일한 이미지-텍스트 쌍에서 이해와 생성 데이터를 쌍으로 구성해 상호 의존성을 높인 점이 특징입니다. 생성 태스크에서 GenEval 0.87, 이해 태스크에서 MME 1699.5를 기록했지만, 학습에 대규모 데이터와 compute가 필요할 것으로 보입니다.
Nanjing University가 멀티모달 이해와 생성을 통합한 UniDDT를 공개했습니다. Noisy ViT 인코더로 잠재 공간을 통일해 두 태스크 간 충돌을 줄인 점이 핵심입니다.
핵심 결론
- 생성 — GenEval 0.87, DPG 86.9 — 통합 모델로서 경쟁력 있는 생성 성능을 보입니다.
- 이해 — MME 1699.5, SEEDbench 76.5 — 이해 태스크에서도 준수한 점수를 기록했습니다.
방법
- Noisy ViT — ViT 인코더에 noise를 추가해 학습하며, 잠재 공간을 이해와 생성 모두에 공유되는 표현으로 만듭니다.
- 디코더 분리 — diffusion 디코더를 LLM 디코딩과 별도로 두어 생성 디코딩이 텍스트 디코딩에 간섭하지 않도록 했습니다.
- 데이터 쌍 — 같은 이미지-텍스트 쌍에서 이해용(캡셔닝)과 생성용(텍스트-이미지) 데이터를 동시에 구성해 상호 이점을 활용합니다.
한계·조건
- 리소스 — 논문에 compute 규모가 명시되지 않았으나, Noisy ViT + diffusion 디코더 구조는 상당한 학습 비용이 예상됩니다.
- 재현성 — 코드와 모델 가중치는 아직 공개되지 않았습니다.
- 벤치 — 생성 벤치는 주로 객체 수·색상·위치 등 단순 태스크 위주로, 고품질 이미지 생성 평가는 추가로 필요합니다.
편집자 한 줄
통합 모델에서 이해와 생성 성능을 동시에 올리기 어려운 점을 감안하면, 두 태스크 모두 준수한 점수를 낸 것은 인상적입니다. 다만 학습 비용과 코드 공개 여부가 실용성의 관건이 될 듯합니다.
- #multimodal
- #unified-model
- #diffusion
- #vit
- #nanjing-university
Nanjing University