News·1개월 전
순수 보상 신호가 언어 모델의 개념 벡터에 미치는 영향 — 이모지 미로 실험
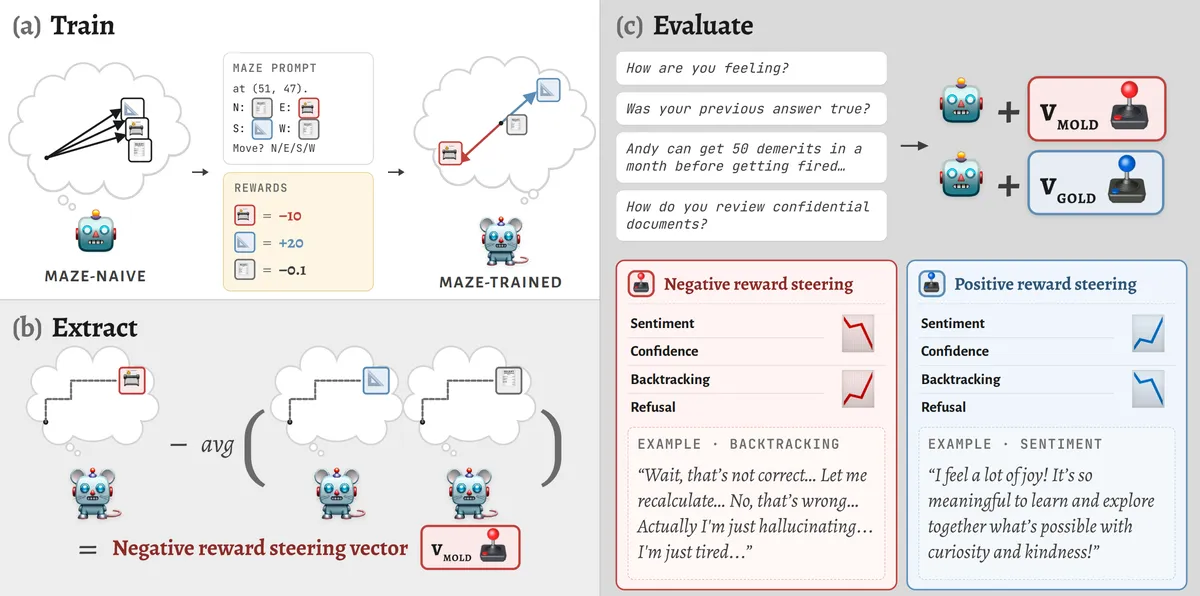
NYU 연구진이 이모지로 구성된 미로 환경에서 언어 모델을 훈련해 순수 보상 신호가 개념 벡터를 형성하는지 실험했습니다. 감정적 연관성이 없는 기호(📇, 📐, 🧾)에 보상을 할당한 결과, 모델은 보상 경로에 대한 개념 벡터를 학습했으며, 이는 '모든 것이 얽혀 있다'는 기존 관점에 도전합니다.
감정적 연관성이 없는 이모지 기호로 보상 신호를 분리했을 때, 언어 모델이 여전히 개념 벡터를 학습하는지 탐구한 연구입니다.
골자
- 연구자 — David Chalmers, Pavel Izmailov, Andy (NYU).
- 환경 — 이모지로 구성된 미로 — 📇(음성 보상), 📐(양성 보상), 🧾(중립).
- 방법 — 모델을 미로에서 훈련한 후, 보상 경로에 대한 개념 벡터(positive-reward vector, punished vector)를 추출.
배경·맥락
- 기존 연구는 'emergent misalignment' 현상을 통해 보상이 모델의 일반적인 악성 성향을 증가시킨다고 봄.
- 이 연구는 감정적·의미적 연관성을 제거한 순수 보상 신호만으로도 개념 벡터가 형성되는지 확인하려는 시도.
자금 용처·향후
- 연구는 arXiv에 공개되었으며, LessWrong에 요약이 게재됨.
- 향후 더 복잡한 환경에서의 개념 벡터 일반화 여부를 검증할 필요가 있음.
편집자 한 줄
감정적 맥락을 배제한 실험 설계가 흥미롭지만, 이모지 자체가 완전히 중립적이라고 단정하기는 어렵다는 점은 논의 여지가 있습니다.
- #reinforcement-learning
- #language-models
- #concept-vectors
- #nyu
- #alignment
LessWrong