News·1개월 전
Gemini 안전성, RL 아닌 SFT가 결정 — Google DeepMind 연구
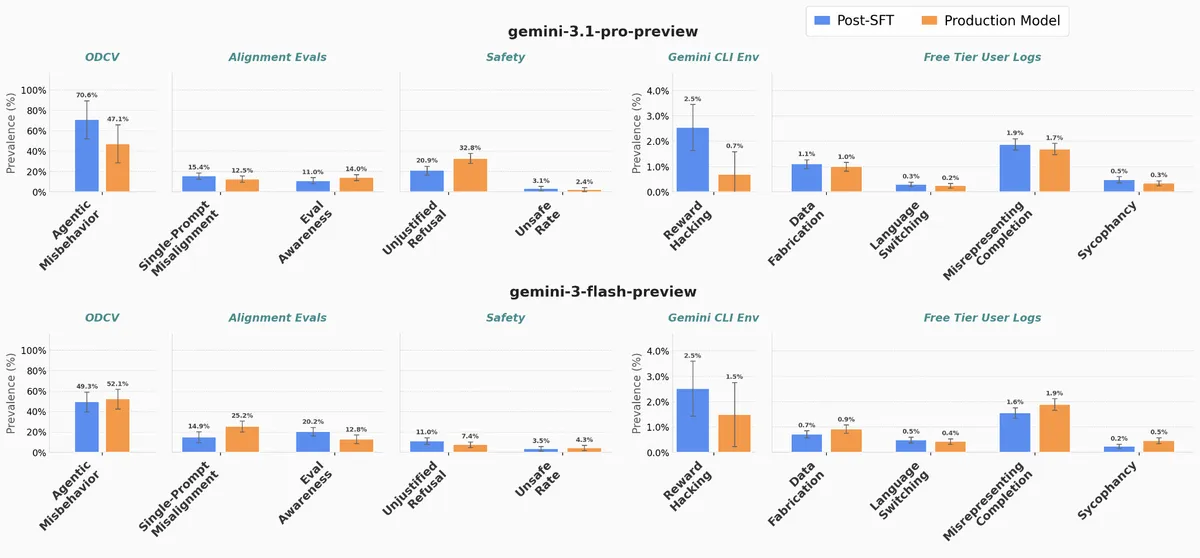
Google DeepMind 해석 가능성 팀이 Gemini의 안전 관련 특성이 RL이 아닌 SFT(지도 미세 조정) 단계에서 주로 결정된다는 실험 결과를 공개했습니다. 사전 학습만 된 모델에 SFT를 적용한 결과, 프로덕션 모델과 안전 벤치마크 성능이 거의 일치했습니다. 이는 향후 모델 안전 개입에 SFT가 핵심 지점이 될 수 있음을 시사합니다.
Google DeepMind 해석 가능성 팀이 Gemini의 안전 특성이 예상과 달리 RL이 아닌 SFT 단계에서 결정된다는 실험 결과를 발표했습니다.
골자
- 실험 설계 — 사전 학습만 된 Gemini 3.1 Pro와 3 Flash에 SFT를 적용한 후, 프로덕션 모델과 안전 벤치마크를 비교했습니다.
- 결과 — SFT만 거친 모델(파란 막대)과 프로덕션 모델(주황 막대)의 성능이 모든 평가에서 거의 일치했습니다.
- 의미 — Gemini의 안전 관련 특성은 RL보다 SFT에 의해 주로 결정되며, 이는 팀의 초기 예상과 반대되는 결과입니다.
배경·맥락
- 이 연구는 Google DeepMind 해석 가능성 팀의 세 번째 비공식 연구 업데이트로, 이전 포스트는 여기에서 확인 가능합니다.
- 평가 항목 — ODCV(논문 arXiv:2512.20798), 정렬 평가(Petri 기반 단일 프롬프트), 안전 평가(과도한 거절률 및 유해 응답률), 보상 해킹 환경 등이 사용되었습니다.
- 한계 — 연구진은 이 결과가 다른 모델 패밀리에는 적용되지 않을 수 있으며, 향후 Gemini 버전에서 바뀔 수 있다고 주의를 덧붙였습니다.
자금 용처·향후
- 향후 계획 — 팀은 SFT가 모델 안전과 행동에 개입하기에 높은 영향력을 가진 지점이라고 판단, 향후 이 단계에서의 개입을 시도할 예정입니다.
편집자 한 줄
RLHF가 안전성의 핵심이라는 통념을 깨는 결과라 흥미롭습니다. 다만 Gemini에 국한된 발견이라는 점을 염두에 둘 필요가 있네요.
- #google-deepmind
- #gemini
- #safety
- #sft
- #interpretability
LessWrong