News·1개월 전
딥러닝 샘플 효율 격차 해소 — 인간 vs AI 비교의 함정
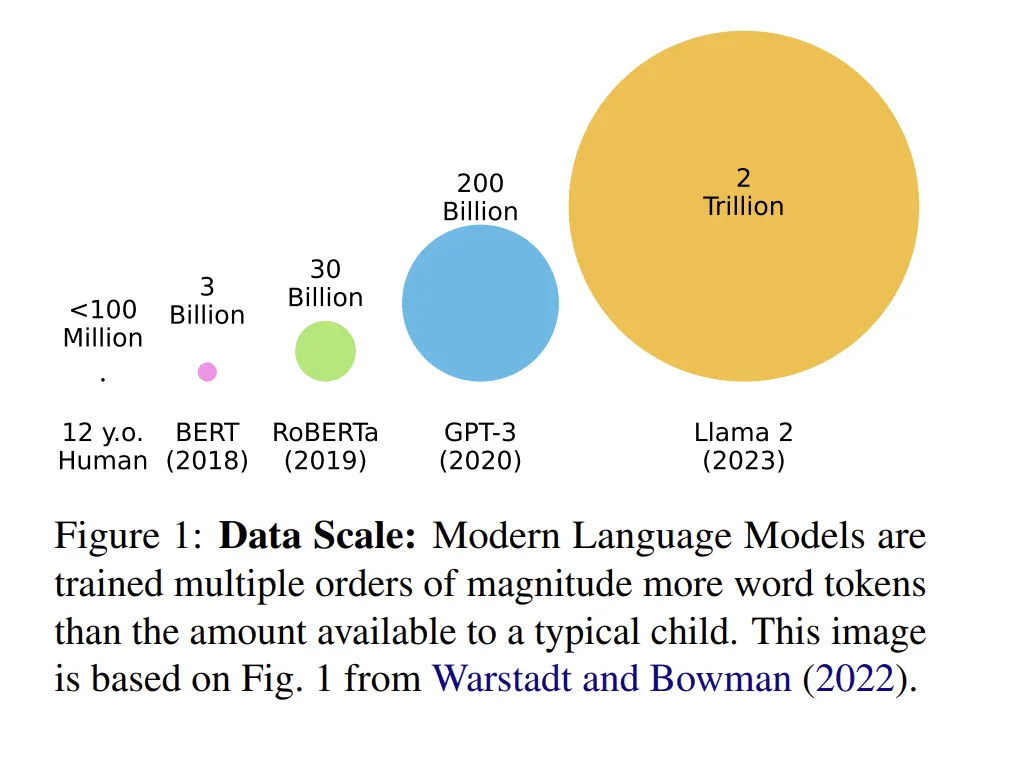
LessWrong 에 올라온 글에서 딥러닝의 샘플 비효율이 과장되었다고 주장합니다. 인간은 사전 학습·모델 기반 RL·진화적 선험을 갖춘 반면, 네트워크는 처음부터 학습하므로 단순 비교는 무의미하다는 겁니다. 실제 효율 개선 여지는 있지만, 대부분은 더 많은 컴퓨트를 요구할 가능성이 높습니다.
딥러닝이 인간보다 샘플 비효율적이라는 통념을 반박하는 글이 LessWrong 에 올라왔습니다.
골자
- 주장 — 딥러닝의 샘플 효율 격차는 대부분 사과-오렌지 비교에서 비롯됩니다.
- 비교 — 인간은 사전 학습·모델 기반 RL·진화적 선험을 갖추고 시작하지만, 네트워크는 처음부터 학습합니다.
- 예시 — LLM 은 수십 조 토큰으로 학습하지만, 12세 아동은 약 1억 단어를 들었습니다. 자율주행은 수십억 마일, 인간은 수십 시간입니다.
배경·맥락
- 오해 — Steven Byrnes 는 이 격차를 알고리즘 혁신의 증거로, Yarrow Bouchard 는 AGI 가 멀었다는 증거로 읽습니다.
- 반박 — 저자는 두 결론 모두 틀렸다고 봅니다. 격차는 대부분 설명 가능한 차이에서 옵니다.
자금 용처·향후
- 효율 개선 — 실제 알고리즘 개선 여지는 있지만, 대부분 더 많은 학습 및 추론 컴퓨트를 요구할 것입니다.
- 시사점 — 인간 수준 AGI 가 소비자 GPU 하나로 가능하다는 Byrnes 의 추측과는 거리가 있습니다.
편집자 한 줄
원문은 LessWrong 의 글로, 샘플 효율 논쟁에 구조적 프레임을 제공합니다. 다만 제안된 개선 방향이 컴퓨트 집약적이라는 점은 주목할 만합니다.
- #deep-learning
- #sample-efficiency
- #agi
- #lesswrong
LessWrong