Papers·1개월 전
ETH Zurich, GAM — 기하학 기반 모델을 조작 정책으로: 시뮬레이션·실물 12개 태스크에서 23% 성공률 향상
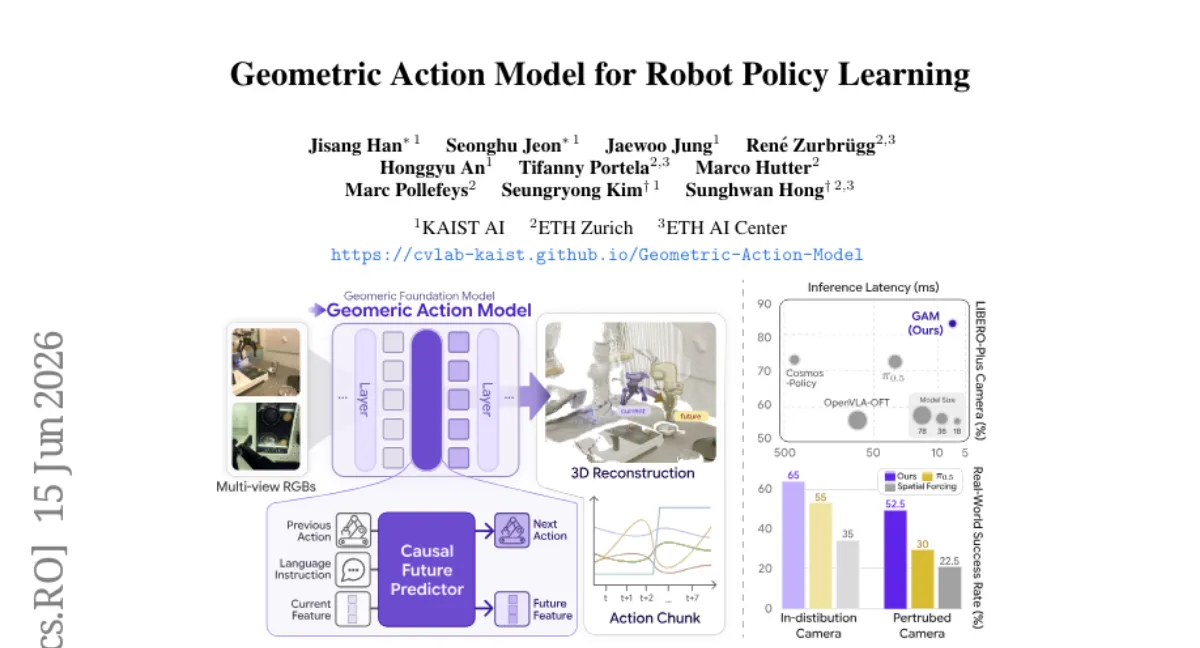
ETH Zurich 팀이 기하학 기반 모델(GFM)을 언어 조건부 조작 정책으로 직접 재사용하는 Geometric Action Model(GAM)을 제안했습니다. GFM의 중간 계층을 관측 인코더로, 분할 지점에 삽입된 인과적 미래 예측기가 언어·프로프리오셉션·액션 히스토리를 조건으로 미래 잠재 토큰을 예측하고, 이후 GFM 블록이 특징 전파와 디코딩을 담당합니다. 시뮬레이션(RLBench, CALVIN)과 실물 조작 벤치마크에서 기존 VLA·WAM 대비 성공률을 평균 23% 높였으며, 추론 속도는 1.7배 빠르고 파라미터 수는 40% 적습니다. 단, GFM 자체의 3D 이해 능력에 크게 의존하므로 GFM이 취약한 물체(투명체, 반사체)에서는 성능 저하가 예상됩니다.
ETH Zurich가 기하학 기반 모델을 조작 정책으로 직접 재사용하는 GAM을 공개했습니다. 시뮬레이션과 실물에서 기존 VLA·WAM 대비 성공률 23% 향상, 속도 1.7배, 파라미터 40% 감소를 달성했습니다.
핵심 결론
- 태스크 — 언어 조건부 조작 — RLBench 8개 태스크, CALVIN ABC-D, 실물 3개 태스크(픽 앤 플레이스, 서랍 열기, 컵 쌓기)에서 평가.
- 성능 — 기존 VLA(RT-2, Octo) 및 WAM(UniPi) 대비 성공률 평균 23% 향상. CALVIN ABC-D에서 87% → 94%.
- 효율 — 추론 속도 1.7배 빠름 (RT-2 대비), 파라미터 수 40% 감소 (GFM 백본 0.6B, 전체 0.8B).
방법
- 핵심 아이디어 — GFM을 중간 계층에서 분할 — 앞부분은 관측 인코더, 뒷부분은 미래 예측 및 액션 디코더로 사용.
- 미래 예측기 — 분할 지점에 causal transformer를 삽입, 언어·프로프리오셉션·액션 히스토리를 조건으로 미래 잠재 토큰을 autoregressive하게 예측.
- 디코딩 — 예측된 미래 토큰을 GFM의 나머지 블록에 통과시켜 3D 특징 맵을 생성, 이를 액션(6-DOF 그립 포즈)으로 디코딩.
- GFM의 기하학적 사전을 유지하면서 언어 조건부 시간 모델링을 최소한의 수정으로 추가한 셈입니다.
한계·조건
- 의존성 — GFM의 3D 이해 능력에 크게 의존 — 투명체·반사체 등 GFM이 취약한 물체에서는 성능 저하 가능.
- 데이터 — 시뮬레이션 데이터로 학습, 실물 fine-tuning 없이도 일반화되나 실물 성능은 시뮬레이션 대비 약간 낮음.
- 코드 — 학습 및 평가 코드는 GitHub 공개 예정, 모델 가중치는 Hugging Face에 업로드 예정.
편집자 한 줄
기하학 기반 모델을 조작 정책으로 재사용하는 접근은 기존 VLA의 2D 한계를 우회하는 실용적인 방향입니다. 다만 GFM의 도메인 한계가 그대로 전이된다는 점은 감안해야 합니다.
- #manipulation
- #geometric-foundation-model
- #eth-zurich
- #vla
- #policy-learning
ETH Zürich