Papers·1개월 전
멀티 이터레이션 경험 내재화에서 붕괴 방지 레시피 — 원칙 수준 경험, 단계별 주입, 오프-폴리시 증류
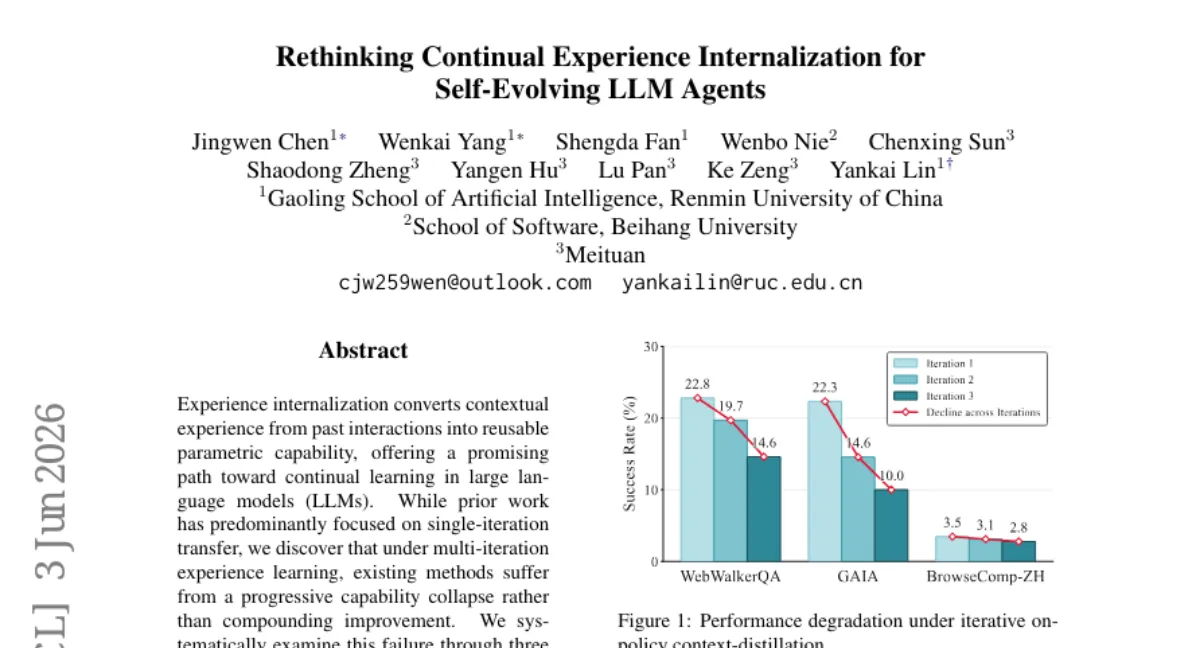
LLM의 경험 내재화(experience internalization)를 멀티 이터레이션으로 확장할 때 기존 방식은 점진적 성능 붕괴를 겪습니다. 이 연구는 세 가지 핵심 차원—경험 세분성(원칙 수준이 인스턴스 수준보다 지속적), 주입 패턴(단계별 주입이 전역 주입보다 우수), 내재화 방식(오프-폴리시 컨텍스트 증류가 온-폴리시보다 안정적)—을 체계적으로 분석해 안정적이고 지속 가능한 내재화 레시피를 제시합니다. 단, 실험은 주로 tool use 태스크에 국한되어 일반화 가능성은 추가 검증이 필요합니다.
멀티 이터레이션 경험 내재화에서 발생하는 성능 붕괴를 세 가지 차원으로 분석하고 안정적인 학습 레시피를 제안한 연구입니다.
핵심 결론
- 문제 — 기존 경험 내재화는 단일 이터레이션에 집중했으나, 멀티 이터레이션에서는 성능이 점진적으로 붕괴합니다.
- 해결 — 원칙 수준 경험, 단계별 주입, 오프-폴리시 컨텍스트 증류의 조합이 안정적인 내재화를 가능하게 합니다.
방법
- 경험 세분성 — 원칙(principle) 수준 경험은 인스턴스(instance) 수준보다 추상화된 전략을 제공해 여러 이터레이션에 걸쳐 지속됩니다.
- 주입 패턴 — 단계별(step-wise) 주입은 중간 결정 상태와 경험을 정렬해 장기 tool use 태스크에서 효과적입니다.
- 내재화 방식 — 오프-폴리시 컨텍스트 증류는 고품질 교사 궤적을 사용해 온-폴리시 증류보다 안정적인 학습 신호를 제공합니다.
한계·조건
- 태스크 범위 — 실험은 주로 tool use 환경에서 수행되어, 다른 도메인(예: 대화, 추론)에서의 일반화는 추가 검증이 필요합니다.
- 코드 공개 — 코드 공개 여부는 논문에 명시되지 않았습니다.
편집자 한 줄
멀티 이터레이션 학습에서의 붕괴를 체계적으로 분석하고 실용적인 레시피를 제시한 점이 인상적입니다. 다만, 원칙 수준 경험의 추출 방법에 대한 구체적인 설명이 더 필요해 보입니다.
- #continual-learning
- #experience-internalization
- #llm
- #tool-use
Jingwen Chen