Papers·1개월 전
장문 음성 생성 평가 벤치마크 SwanBench-Speech — 17개 시나리오, 7개 자동 지표
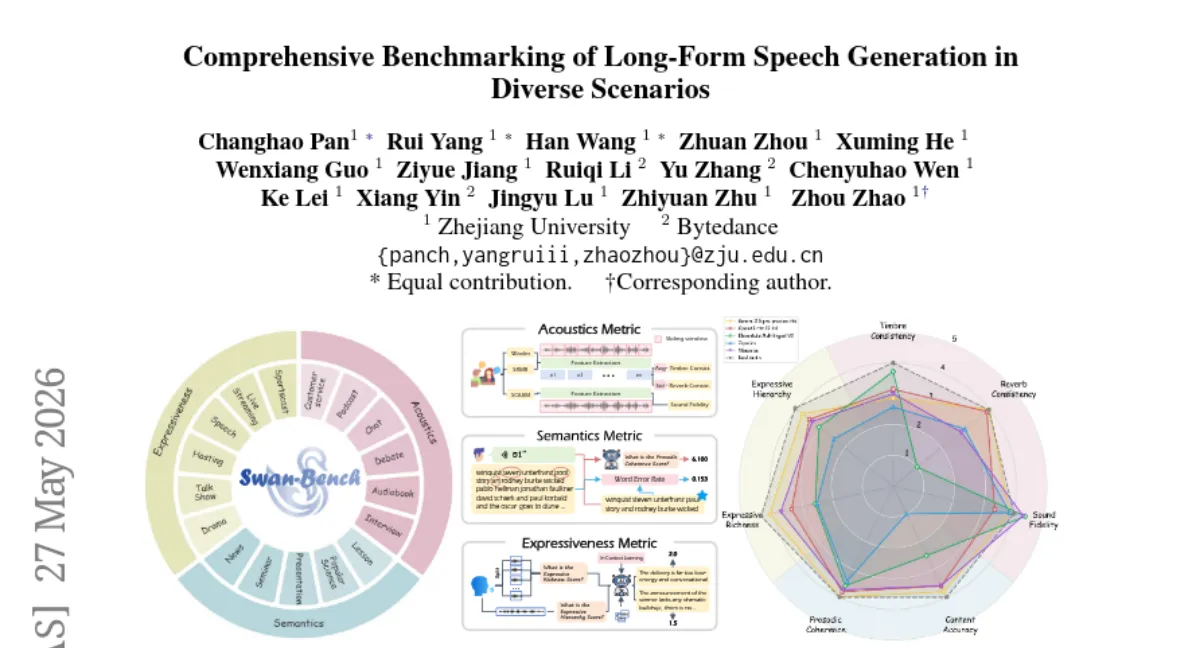
Zhejiang University 팀이 장문 음성 생성의 품질을 음향·의미·표현력 세 축으로 분해해 평가하는 벤치마크 SwanBench-Speech를 제안했습니다. 1,101개 샘플, 17개 음성 시나리오를 포함하며 7개 자동 지표로 일관성·계층 구조 등을 측정합니다. 실험 결과, 현 모델들은 고표현력 시나리오에서 여전히 어려움을 겪고 실제 녹음 대비 일관성과 계층 구조에서 현저한 격차를 보였습니다.
장문 음성 생성 평가의 공백을 메우기 위해, 음향·의미·표현력을 아우르는 종합 벤치마크 SwanBench-Speech가 공개되었습니다.
핵심 결론
- 범위 — 1,101개 샘플, 17개 음성 시나리오(장문 생성·대화 생성)로 기존 벤치마크보다 도메인 폭이 넓습니다.
- 지표 — 음향·의미·표현력 세 축에서 7개 자동 평가 지표를 정의해 일관성·계층 구조를 정량화합니다.
- 격차 — 현 모델들은 고표현력 시나리오에서 성능이 크게 떨어지며, 실제 녹음과의 일관성·계층 구조 차이가 두드러집니다.
방법
- 구성 — SwanBench-Speech는 장문 음성 생성과 대화 생성 두 태스크로 나뉘며, 각각 음향·의미·표현력 난이도를 고려해 설계되었습니다.
- 자동 평가 — 7개 지표는 음향 충실도, 의미 일관성, 표현력 등급 등을 포함하며 사람 평가 없이도 재현 가능한 평가를 목표로 합니다.
- 데이터 — 공개 데이터셋과 자체 수집 데이터를 혼합해 17개 시나리오를 커버합니다.
한계·조건
- 범위 — 현재는 영어 음성만 포함하며, 다국어·악센트 다양성은 추후 확장이 필요합니다.
- 자동 지표 — 7개 지표 모두 자동화되었지만, 사람 청취 평가와의 상관관계 검증이 추가로 필요합니다.
- 코드 — 벤치마크 데이터와 평가 코드는 공개 예정이나 현재 시점에서는 제한적으로만 접근 가능합니다.
편집자 한 줄
장문 음성 생성 평가의 표준화를 시도한 점은 의미 있지만, 자동 지표의 신뢰성과 다국어 확장이 관건이 될 듯합니다.
- #speech-generation
- #benchmark
- #long-context
- #zhejiang-university
Zhejiang University