Papers·1개월 전
Jina AI, frozen-encoder 방식으로 멀티모달 임베딩 모델 공개 — 학습 파라미터 0.35% 만 훈련
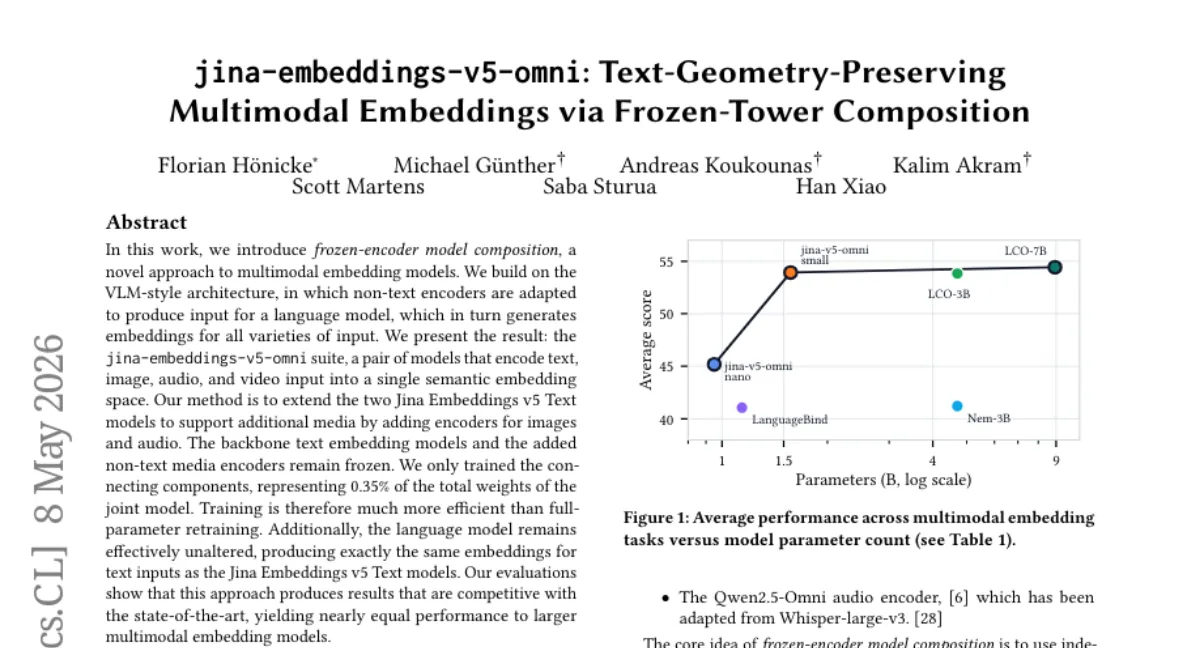
Jina AI가 텍스트·이미지·오디오·비디오를 단일 임베딩 공간으로 인코딩하는 jina-embeddings-v5-omni 스위트를 공개했습니다. 기존 텍스트 임베딩 모델(Jina Embeddings v5 Text)의 백본과 새로 추가한 이미지·오디오 인코더는 모두 고정(frozen)하고, 연결 모듈만 학습했는데 이는 전체 가중치의 0.35%에 불과합니다. 텍스트 입력에 대한 임베딩은 기존 모델과 완전히 동일하게 유지되며, 더 큰 멀티모달 모델과 견줄 만한 성능을 보입니다. 단, 이 방식은 VLM-style 아키텍처에 의존하므로 인코더-디코더 구조의 모델에는 바로 적용하기 어려울 수 있습니다.
- #multimodal
- #embeddings
- #frozen-encoder
- #jina-ai
Jina AI