News·1개월 전
활성 정합 미세조정으로 LLM 은닉 행동 탐지 — 새로운 프리프린트
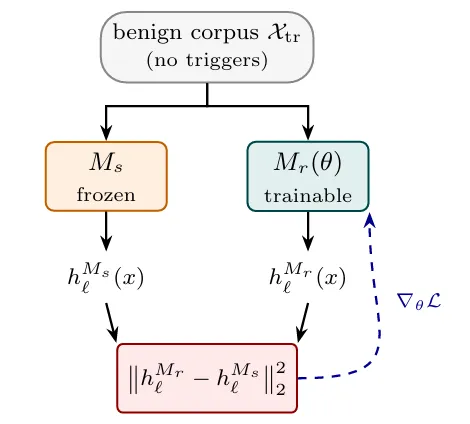
LessWrong 에 게재된 프리프린트에서, 의심 모델의 잔차 스트림 활성을 깨끗한 참조 모델이 모방하도록 훈련해 은닉 행동(백도어, 리워드 해킹 등)을 탐지하는 방법을 제시했습니다. 참조 모델은 정상 프롬프트에서는 잘 맞지만, 은닉 행동이 발동되는 지점에서는 활성 패턴이 급격히 벗어나 탐지가 가능해집니다. 기존 방법보다 사전 가정이 적어 실용적입니다.
의심 모델의 잔차 활성을 깨끗한 참조 모델이 모방하도록 훈련해, 정상 범위를 벗어나는 은닉 행동을 잡아내는 방법입니다.
골자
- 방식 — 의심 모델(suspect)의 잔차 스트림 활성(~1만 WildChat 프롬프트)을 깨끗한 공개 모델(reference)이 재현하도록 미세조정.
- 핵심 — 참조 모델은 정상 프롬프트에서는 거의 완벽하게 맞지만, 백도어·리워드 해킹 등 은닉 행동이 포함된 입력에서는 활성 차이가 급증 — 이 차이가 탐지 신호가 됩니다.
- 장점 — 트리거 형태, 레이블된 배반 예시, 중독 훈련 데이터 등 사전 가정이 거의 필요 없습니다.
배경·맥락
- 기존 백도어 탐지는 특정 트리거 형태를 가정하거나 중독 데이터셋을 알아야 했지만, 이 방법은 모델 아키텍처만 같으면 적용 가능합니다.
- 참조 모델이 의심 모델과 같은 프리트레이닝 베이스를 공유할 때 활성 정합이 특히 잘 된다고 합니다.
자금 용처·향후
- 적용 — 백도어 외에도 샌드배깅, 검열 회피, 리워드 해킹 등 다양한 은닉 행동 탐지에 쓸 수 있습니다.
- 한계 — 프리프린트 단계로, 대규모 모델에서의 실증과 다른 아키텍처로의 일반화는 추가 연구가 필요합니다.
편집자 한 줄
트리거를 전혀 모르는 상황에서도 탐지가 가능하다는 점이 흥미롭습니다. 다만 참조 모델이 같은 베이스를 공유해야 한다는 조건이 실용성을 제한할 수도 있겠네요.
- #llm
- #safety
- #backdoor-detection
- #activation-matching
- #mechanistic-interpretability
LessWrong