News·4시간 전
LLM 기반 피처 발견: 모델 행동을 블랙박스로 분석하는 방법
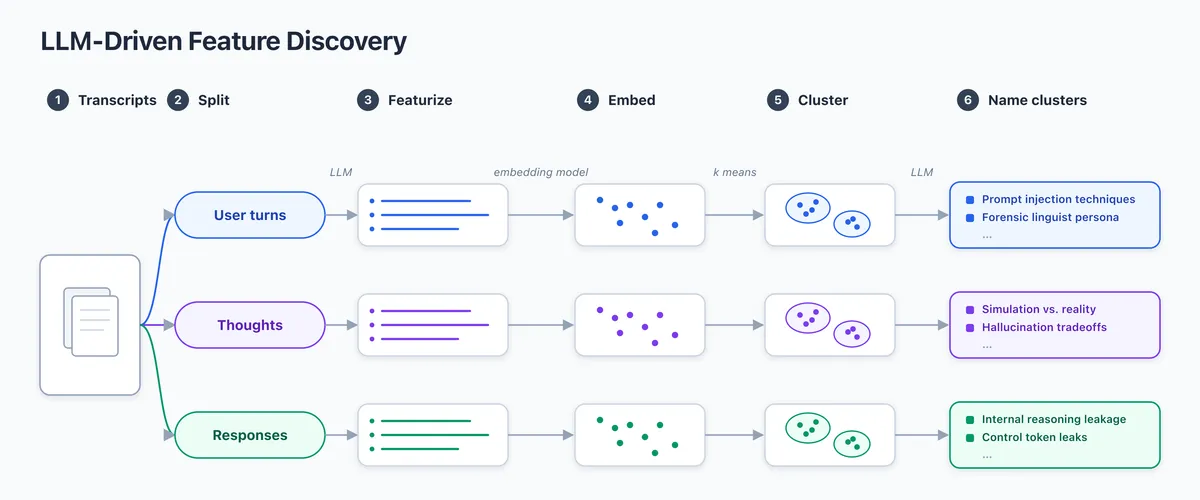
LessWrong 에 게재된 단기 탐구 프로젝트로, LLM autorater 를 활용해 모델의 transcript 에서 피처를 추출하고 클러스터링하는 방법을 제안했습니다. 사용자 턴·생각·어시스턴트 응답을 분리해 각각 10~20개 피처를 생성하고, semantic embedding 으로 클러스터링한 뒤 LLM 이 레이블을 붙입니다. SAE 와 유사하지만 모델 내부를 보지 않는 '블랙박스 SAE' 성격이며, 기존 EDW 방법보다 단순하고 비지도 방식입니다.
모델의 배포·RL 훈련·평가 등 중요한 분포에서 행동을 정성적으로 이해하기 위한 방법입니다.
골자
- 방법 — transcript 를 사용자 턴·생각·응답으로 분할하고, 각 조각에 대해 블랙박스 LLM autorater 가 10~20개 피처를 생성합니다.
- 클러스터링 — 피처의 semantic embedding 을 구한 뒤, 사용자·생각·응답별로 따로 클러스터링합니다.
- 레이블링 — 클러스터당 100개 랜덤 피처를 LLM 에 주고 '5단어 내 공통 주제'를 요약하게 합니다.
배경·맥락
- 이 방법은 SAE 와 유사한 문제를 풀지만 모델 내부를 사용하지 않아 '블랙박스 SAE'로 불립니다.
- 기존 EDW(Explaining Datasets in Words)와 비슷하나, EDW 는 임베딩 방향을 최적화하고 반복이 필요한 반면, 이 방법은 LLM 호출 한 번으로 끝나고 비지도 방식입니다.
자금 용처·향후
- EDW 가 특정 통계 오차 최소화에 강점이 있다면, 이 방법은 단순성과 확장성에서 유리합니다.
편집자 한 줄
모델 행동 분석 도구로 간단한 편이라, 해석 가능성 연구에 실용적으로 써볼 만합니다.
- #llm
- #feature-discovery
- #interpretability
- #lesswrong
LessWrong