Papers·1개월 전
북경대, 추론 자원 예산 최적화 기법 CLEAR 제안 — 제한된 토큰 예산에서 정확도 최대 3배 향상
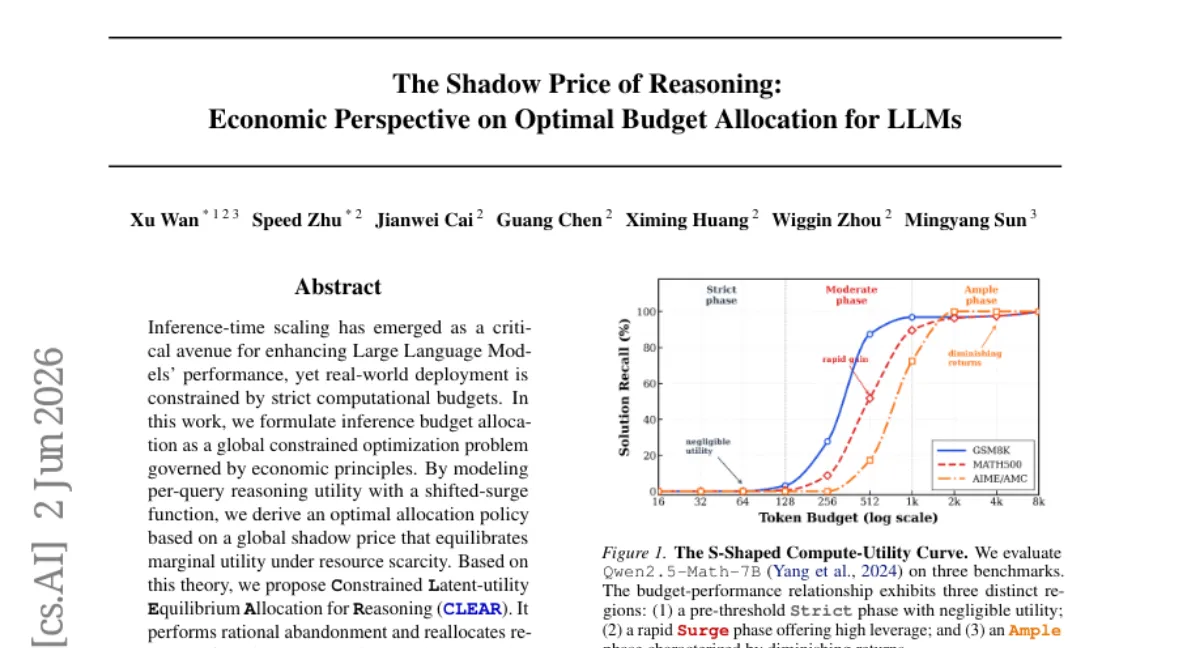
북경대 연구팀이 제한된 추론 자원 예산 하에서 LLM 성능을 최적화하는 프레임워크 CLEAR를 제안했습니다. 각 쿼리의 추론 효용을 shifted-surge 함수로 모델링하고, 글로벌 섀도우 프라이스를 기반으로 자원을 재할당하여 수익성 낮은 쿼리는 중단하고 임계치 근처의 쿼리에 집중합니다. 여러 추론 태스크에서 균등 할당 대비 최대 3배의 정확도 향상을 보였으며, 파레토 프론티어를 크게 개선했습니다.
북경대 연구팀이 제한된 추론 자원 예산 하에서 LLM 성능을 최적화하는 경제학 기반 프레임워크 CLEAR를 발표했습니다.
핵심 결론
- 성능 — 자원 부족 환경에서 균등 할당 대비 최대 3배의 글로벌 정확도 향상을 달성했습니다.
- 범위 — 다양한 추론 태스크와 트래픽 스트림에서 파레토 프론티어(총 토큰 비용 대비 평균 정확도)를 유의미하게 개선했습니다.
방법
- 최적화 문제 — 추론 예산 할당을 전역 제약 최적화 문제로 정식화하고, 각 쿼리의 추론 효용을 shifted-surge 함수로 모델링했습니다.
- 할당 정책 — 글로벌 섀도우 프라이스(자원 희소성 하에서 한계 효용을 균형시키는 가격)를 기반으로 최적 할당 정책을 도출했습니다.
- CLEAR — 수익성이 낮은 쿼리는 합리적으로 중단(abandon)하고, 자원을 임계치 근처의 해결 가능한 쿼리에 재할당합니다.
한계·조건
- 가정 — 각 쿼리의 효용 함수 형태를 shifted-surge로 가정했는데, 실제 분포와의 괴리가 있을 수 있습니다.
- 실험 — 특정 모델과 태스크에 국한된 실험 결과로, 일반화 가능성은 추가 검증이 필요합니다.
- 코드 — 논문에서 코드 공개 여부는 명시되지 않았습니다.
편집자 한 줄
경제학 원리를 LLM 추론 최적화에 적용한 점이 신선합니다. 다만 효율성-형평성 트레이드오프가 실제 서비스에서 어떻게 작용할지 지켜볼 필요가 있네요.
- #inference-scaling
- #resource-allocation
- #llm
- #peking-university
- #optimization
Peking University