Papers·1개월 전
상하이교통대, 차원 축소와 표현 공간 정규화로 NTP 한계 극복 — 9B MoE MMLU-Pro 5.7%p 향상
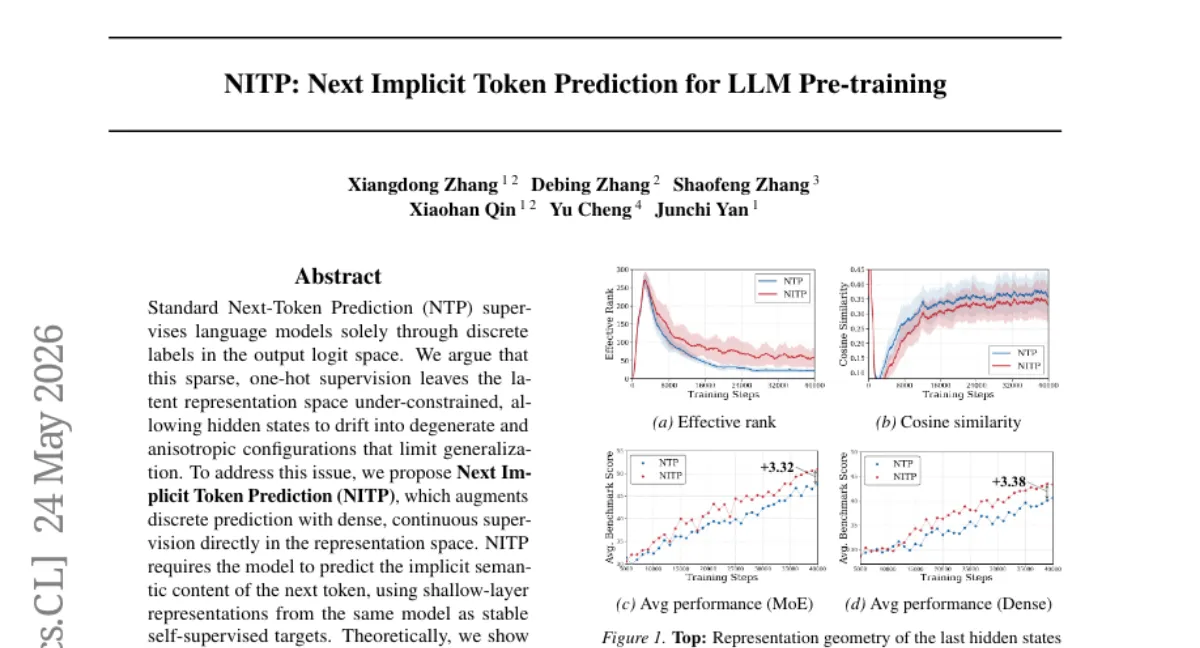
상하이교통대 연구팀이 next-token prediction(NTP)의 희소한 one-hot 감독이 표현 공간을 비대칭·퇴화시키는 문제를 해결하는 NITP(Next Implicit Token Prediction)를 제안했습니다. NITP는 동일 모델의 얕은 층 표현을 self-supervised 타깃으로 삼아, 다음 토큰의 암시적 의미를 연속 공간에서 예측하도록 학습합니다. 0.5B~9B 규모의 dense/MoE 모델에서 일관된 성능 향상을 보였고, 9B MoE 기준 MMLU-Pro 5.7%p, C3 6.4%p, CommonsenseQA 4.3%p 개선했으며 학습 FLOPs는 약 2% 증가, 추론 비용은 동일합니다.
NTP의 one-hot 감독은 표현 공간에 과도한 자유도를 남겨 일반화를 제한한다는 문제를, 연속 공간에서의 밀집 예측으로 해결한 접근입니다.
핵심 결론
- 태스크 — MMLU-Pro, C3, CommonsenseQA 등 다양한 벤치마크에서 일관된 성능 향상.
- 개선폭 — 9B MoE 모델에서 MMLU-Pro 5.7%p, C3 6.4%p, CommonsenseQA 4.3%p 절대 개선.
- 비용 — 학습 FLOPs 약 2% 증가, 추론 오버헤드는 전혀 없음.
방법
- 핵심 아이디어 — 다음 토큰의 원-핫 레이블 대신, 동일 모델의 얕은 층에서 뽑은 표현 벡터를 타깃으로 삼아 연속 공간에서 예측하도록 학습.
- 정규화 효과 — 이론적으로 NITP가 최적화 경관에서 under-constrained 자유도를 줄이고, 표현 공간을 컴팩트하고 구조화된 형태로 유도함을 증명.
- 구현 — 기존 NTP 파이프라인에 간단한 auxiliary loss를 추가하는 형태로, 코드는 GitHub에 공개.
한계·조건
- 모델 규모 — 실험은 0.5B~9B 범위에서만 검증되어, 더 큰 모델에서의 효과는 추가 확인 필요.
- 벤치마크 — 주로 중국어/영어 QA 및 상식 추론에 집중되어, 코드·수학 등 다른 도메인에서의 일반화는 미검증.
- 코드 — GitHub에 구현 공개되어 재현 가능.
편집자 한 줄
추론 비용 증가 없이 표현 공간을 정규화한다는 점이 실용적이네요. 다만 9B MoE에서의 개선이 주로 MMLU-Pro에 집중된 점은 후속 연구에서 더 다양한 태스크로 확인해볼 만합니다.
- #next-token-prediction
- #representation-learning
- #self-supervised-learning
- #moe
- #shanghai-jiao-tong-university
Shanghai Jiao Tong University SAI