Papers·4개월 전
DeFI: VLA 모델에서 시각 예측과 행동 추론 분리 — CALVIN 태스크 길이 4.51, 실제 환경 81.3% 성공률
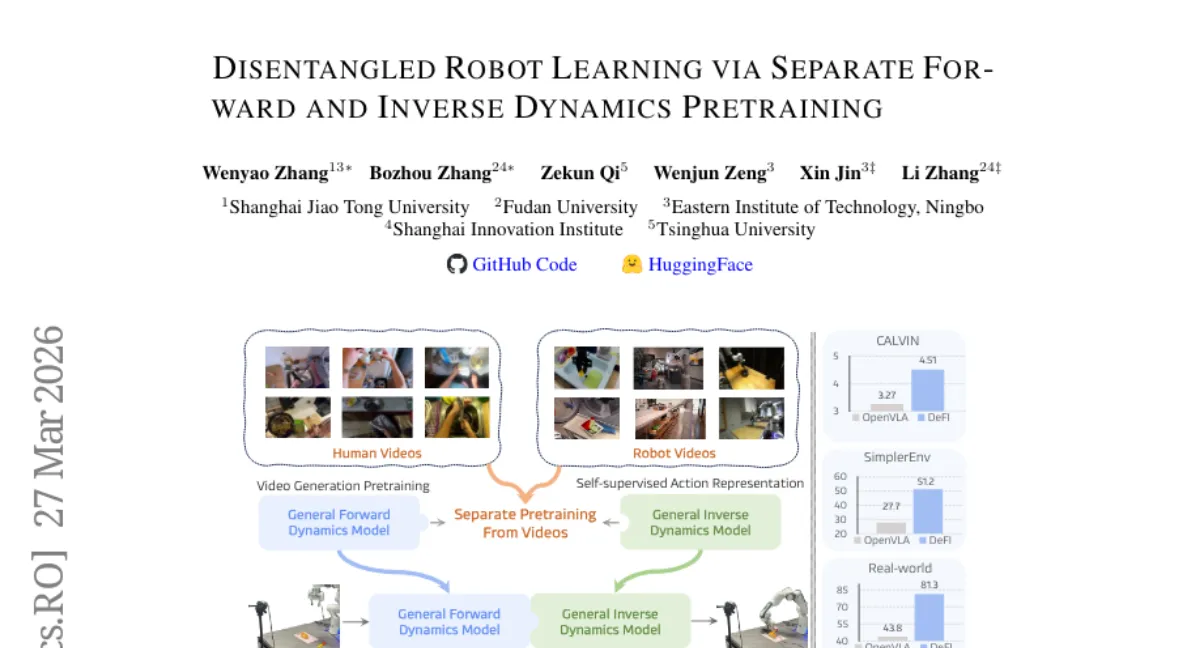
DeFI는 VLA 모델의 2D 영상 예측과 3D 행동 예측 간 불일치 문제를 해결하기 위해 시각 전방 동역학(Forward Dynamics)과 역동역학(Inverse Dynamics) 사전학습을 분리하는 프레임워크입니다. 일반 전방 동역학 모델(GFDM)은 다양한 인간 및 로봇 비디오에서 미래 예측을 학습하고, 일반 역동역학 모델(GIDM)은 레이블 없는 비디오 전이로부터 잠재 행동을 추론하도록 자기지도 학습됩니다. 이 두 모델을 통합해 하위 태스크에서 미세조정하며, CALVIN ABC-D에서 평균 태스크 길이 4.51, SimplerEnv-Fractal에서 51.2%, 실제 환경에서 81.3% 성공률을 기록했습니다. 다만, GFDM과 GIDM의 사전학습에 대규모 비디오 데이터가 필요해 리소스 요구가 크다는 점이 한계입니다.
- #vla
- #robot-learning
- #self-supervised-learning
- #video-prediction
- #defi
Wenyao Zhang