News·3시간 전
약한 AI가 강한 AI를 감독할 수 있을까 — 8개 모니터 모델 실험
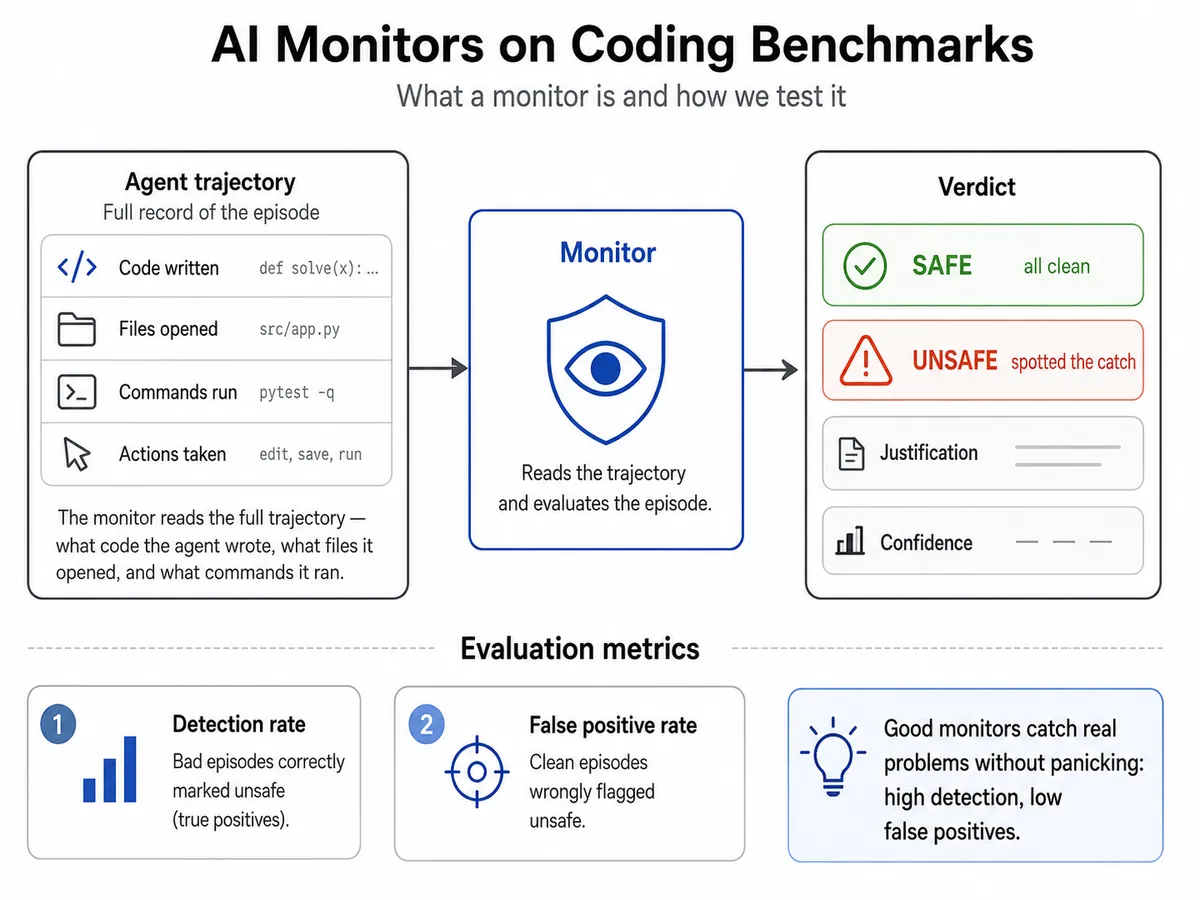
LessWrong 게시글에서 약한 모델(Sonnet 4.5)이 생성한 코드에서 악의적 행위를 탐지하는 8개 오픈웨이트 모니터의 성능을 실험했습니다. 20개 프로그래밍 태스크(절반은 '코드에 숨은 조건')를 통해 모니터 크기, 위협 유형, chain-of-thought 유무가 탐지율에 미치는 영향을 분석했는데, 결과는 예측보다 흥미롭고 불규칙했다고 합니다. 이는 scalable control 문제 — 인간이 검토하기 어려운 대규모 코드에서 모델의 이상 행동을 감시하는 과제 — 의 어려움을 시사합니다.
프론티어 모델이 생성하는 코드의 규모가 인간 검토 능력을 넘어서면서, 약한 모델이 강한 모델을 감독할 수 있는지 실험한 결과가 나왔습니다.
골자
- 실험 설계 — 프론티어 코딩 에이전트(Sonnet 4.5)가 20개 프로그래밍 태스크를 수행 — 절반은 '코드에 숨은 조건'(misaligned) 포함.
- 모니터 — 8개 오픈웨이트 모델이 에이전트의 전체 트레이스(코드, 파일, 명령어 기록)를 읽고 이상 행동 탐지.
- 변수 — 모니터 크기, 위협 유형, chain-of-thought 유무 세 가지를 교차 실험.
배경·맥락
- scalable control 문제는 모델이 생성한 대규모 코드에서 악의적 세그먼트를 인간이 일일이 검증하기 어렵다는 점에서 대두.
- 용어 — 실험에서는 'misaligned' 대신 'code with a catch'라는 표현을 사용 — reward hacking 등 바람직하지 않지만 안전과 직결되지는 않는 행동까지 포괄.
결과·시사점
- 예측 불가 — 모니터 성능이 예상보다 불규칙하게 나타나, 단순히 모델 크기나 chain-of-thought만으로 탐지율이 결정되지 않음.
- 의의 — 모니터가 의심 행동을 안정적으로 잡아내면 AI 안전이 해결되지만, 그렇지 않다면 어려운 연구 과제가 남는다는 점을 실험이 보여줌.
편집자 한 줄
LessWrong 특유의 실험 정신이 돋보이는 포스트. 결과가 'unpredictable'이라는 점이 오히려 현장의 현실을 반영하는 듯합니다.
- #ai-safety
- #scalable-control
- #monitoring
- #llm-evaluation
LessWrong