News·1개월 전
약한 심판에게 토론이 도움되는 조건 — 코드·논리 실험 결과
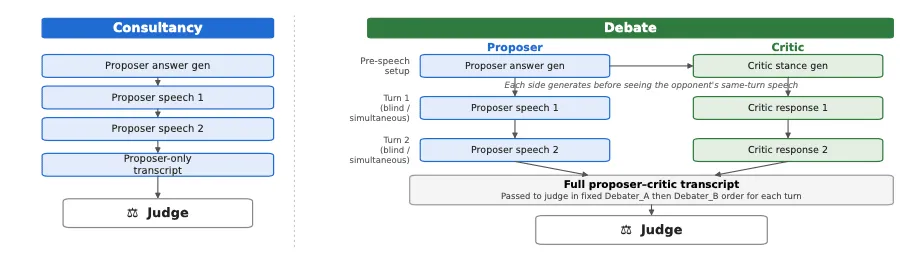
Ethan Elasky·Frank Nakasako(Palaestra Research)와 Naman Goyal(Independent)이 약한 심판이 강한 모델의 답변을 평가할 때 토론(debate)이 도움되는 조건을 코드·논리 태스크로 실험했습니다. 토론은 비평가가 심판보다 답변 분류에 더 뛰어나고, 심판이 비평가의 주장을 요약하지 않고 검증 대상으로 삼을 때만 효과가 있었습니다. 5개 페어링 중 3개에서 토론이 보상 레이블을 개선했지만, 조건이 맞지 않으면 무의미했습니다.
약한 심판이 강한 모델의 답변을 평가할 때 토론이 도움되는 조건을 코드·논리 태스크로 실험한 연구입니다.
골자
- 실험 설계 — 제안자가 코드·논리 태스크에 답변 생성 → 심판이 정답 여부 레이블링. 토론 조건에서는 비평가가 제안자 답변에 동의/반박하며 이유 제시.
- 비교 조건 — 일방향 컨설팅(제안자만 방어, 독립 비평가 없음)과 비교.
- 결과 — 5개 강한 제안자/약한 심판 페어링 중 3개에서 토론이 보상 레이블 개선. 개선된 페어링: Opus 4.6 → Opus 4.5, Gemini 3.1 Pro → Gemini 3 Flash, Qwen3.5-122B → (미기재).
배경·맥락
- 장기 목표는 연구 제안·실험 계획·장기 에이전트 작업 등 인간이나 모델이 답변 품질을 판단하기 어려운 영역에 적용하는 것.
- 태스크 선택 이유 — 코드·ARC 스타일 논리 태스크는 답변을 프로그램으로 검증 가능해 레이블 정확도를 감사할 수 있음.
핵심 통찰
- 도움된 조건 — 비평가가 심판보다 제안자 답변 분류에 더 뛰어나고, 심판이 비평가 주장을 요약하지 않고 검증 대상으로 삼을 때.
- 실패 조건 — 비평가가 심판보다 분류 성능이 낮거나, 심판이 비평가 주장을 수동적으로 수용할 때 토론 효과 없음.
편집자 한 줄
약한 심판이 강한 모델을 평가하는 'debate' 프로토콜은 이론적으로 매력적이지만, 실제 효과는 심판과 비평가의 상대적 역량에 민감하다는 점을 실험으로 확인한 셈입니다.
- #debate
- #reward-labeling
- #alignment
- #ai-safety
- #lesswrong
LessWrong