Papers·1개월 전
AKBE: 에이전트 RL의 지식 경계 강화 — 툴 호출 18% 줄이고 정확도 +1.85
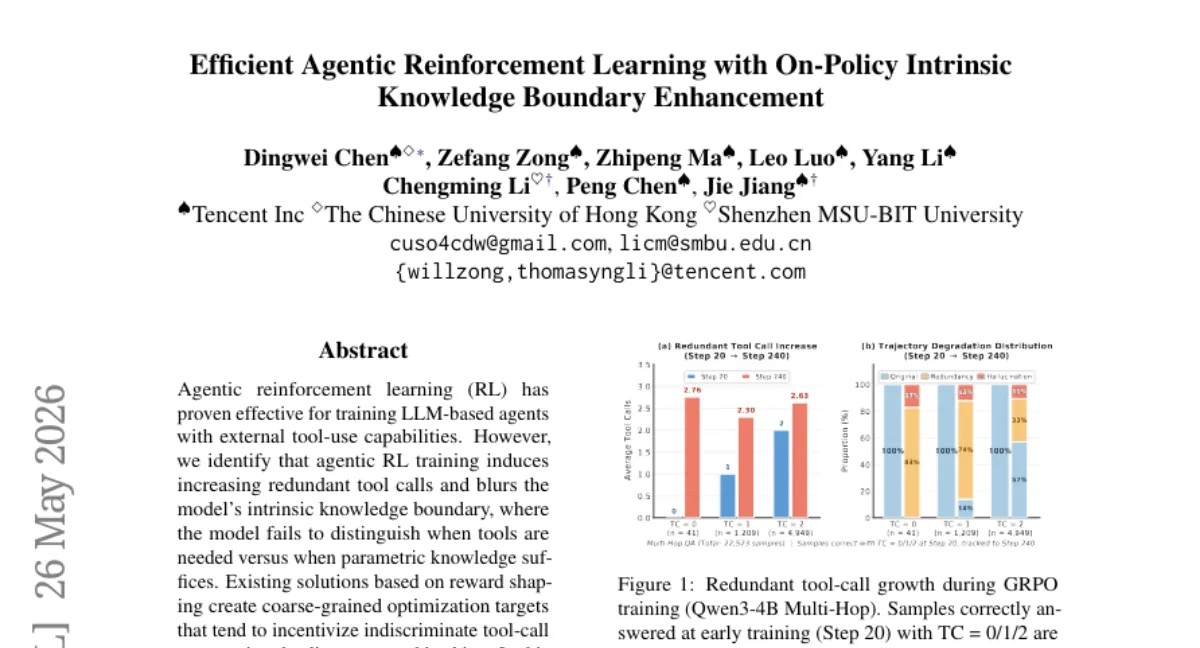
Tencent 팀이 LLM 에이전트의 과도한 툴 호출 문제를 해결하는 AKBE를 제안했습니다. 기존 RL은 모델이 툴이 필요 없는 상황에서도 툴을 호출하는 경향이 있는데, AKBE는 훈련 중 툴 사용 경로와 미사용 경로를 병행 롤아웃하여 질문별 지식 경계를 동적으로 탐지합니다. 7개 QA 벤치마크에서 정확도 평균 +1.85, 툴 호출 18% 감소, 툴 생산성 25% 향상을 달성했습니다. 다양한 RL 알고리즘에 플러그 앤 플레이로 적용 가능하며 코드도 공개되어 있습니다.
Tencent 팀이 에이전트 RL 훈련에서 모델이 불필요한 툴 호출을 반복하고 지식 경계가 흐려지는 문제를 해결하는 AKBE를 공개했습니다.
핵심 결론
- 성능 — 7개 QA 벤치마크에서 평균 정확도 +1.85, 툴 호출 18% 감소, 툴 생산성 25% 향상.
- 호환성 — 다양한 RL 알고리즘(PPO, GRPO 등)에 플러그 앤 플레이로 적용 가능.
방법
- 듀얼 패스 — 훈련 중 각 질문에 대해 툴 사용 경로와 미사용 경로를 병행 롤아웃하여 모델의 지식 경계를 동적으로 탐지합니다.
- 신호 설계 — 두 경로의 정답 여부를 비교해 궤적을 분류하고, 각 질문에 최적화된 툴 사용 패턴을 유도하는 감독 신호를 생성합니다.
- 이 신호를 기존 에이전트 RL 훈련 루프에 자연스럽게 통합하는 점이 핵심입니다.
한계·조건
- 환경 — 실험은 7B~70B 규모의 LLM 기반 에이전트에서 수행되었으며, 더 큰 모델에서의 효과는 추가 검증이 필요합니다.
- 코드 — GitHub에 공개되어 재현 가능합니다.
편집자 한 줄
툴 호출 효율과 정확도를 동시에 개선한 점이 인상적이며, 특히 듀얼 패스 롤아웃 아이디어는 간단하면서도 효과적입니다.
- #agentic-rl
- #tool-use
- #knowledge-boundary
- #tencent
Tencent