News·3시간 전
LLM, 자신의 활성화에 주입된 개념을 언어로 식별할 수 있다
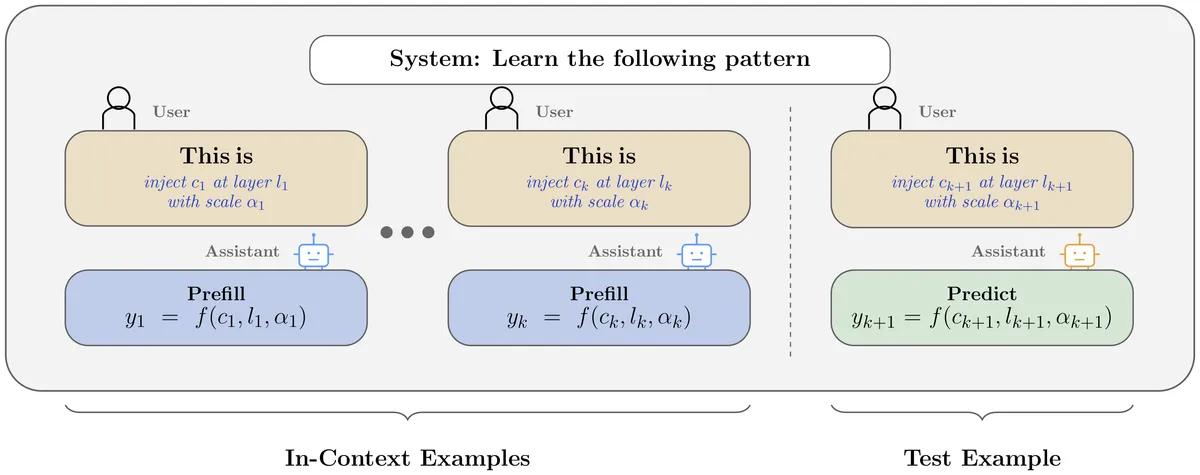
SPAR 연구진이 LLM의 활성화에 steering vector를 주입하고, 모델이 주입된 위치(초기/중간/후기), 상대적 크기(낮음/중간/높음), 의미적 조건을 언어로 식별할 수 있는지 실험했습니다. Qwen3-32B와 Gemma-4-31B가 모든 과제에서 높은 정확도를 보였고, Gemma-4-31B는 특정 주입을 식별해 행동을 조건화하는 zero-shot 일반화도 가능했습니다. 5개 모델(Qwen3-32B, Olmo3.1-32B, Gemma-4-31B, Qwen3-8B, Olmo3-7B)을 CoT 없이 테스트했습니다.
LLM이 자신의 내부 활성화에 주입된 정보를 언어로 회복할 수 있는지 테스트한 SPAR 연구 결과입니다.
골자
- 실험 설계 — steering vector를 주입하고 모델이 주입 영역(초기/중간/후기), 상대적 크기(낮음/중간/높음), 특정 의미 조건을 식별하도록 요구.
- 모델 — Qwen3-32B, Olmo3.1-32B, Gemma-4-31B, Qwen3-8B, Olmo3-7B — 모두 CoT 비활성화.
- 결과 — Qwen3-32B와 Gemma-4-31B가 모든 과제에서 높은 정확도와 일반화 달성.
배경·맥락
- SPAR(Supervised Patching and Reasoning) 프로그램의 일환으로, Mirko Bronzi와 Damiano Fornasiere가 멘토링.
- steering vector를 통해 모델 내부 표현을 외부에서 조작하고, 모델이 이를 인지하는지 검증하는 메커니스틱 해석 가능성 연구.
주목할 점
- Gemma-4-31B — 특정 주입을 식별해 행동을 조건화하는 zero-shot 일반화가 가능 — 주입된 개념을 인지하고 그에 따라 출력을 조절할 수 있음.
- 의의 — 모델이 자신의 내부 상태에 대한 메타인지를 가질 가능성을 시사하며, 정렬 및 제어 연구에 새로운 방향 제시.
편집자 한 줄
모델이 자신의 활성화를 '읽는' 능력은 안전성 측면에서 양날의 검 — 제어 가능성을 높이지만, 조작 탐지에도 쓸 수 있다는 점이 흥미롭습니다.
- #llm
- #steering-vectors
- #mechanistic-interpretability
- #spar
LessWrong