Papers·1개월 전
NVIDIA, Vygotsky 영감 받은 지식 증류 ZPPO — 0.8B 모델에서 27B 교사 증류, 31개 벤치마크 평균 12% 향상
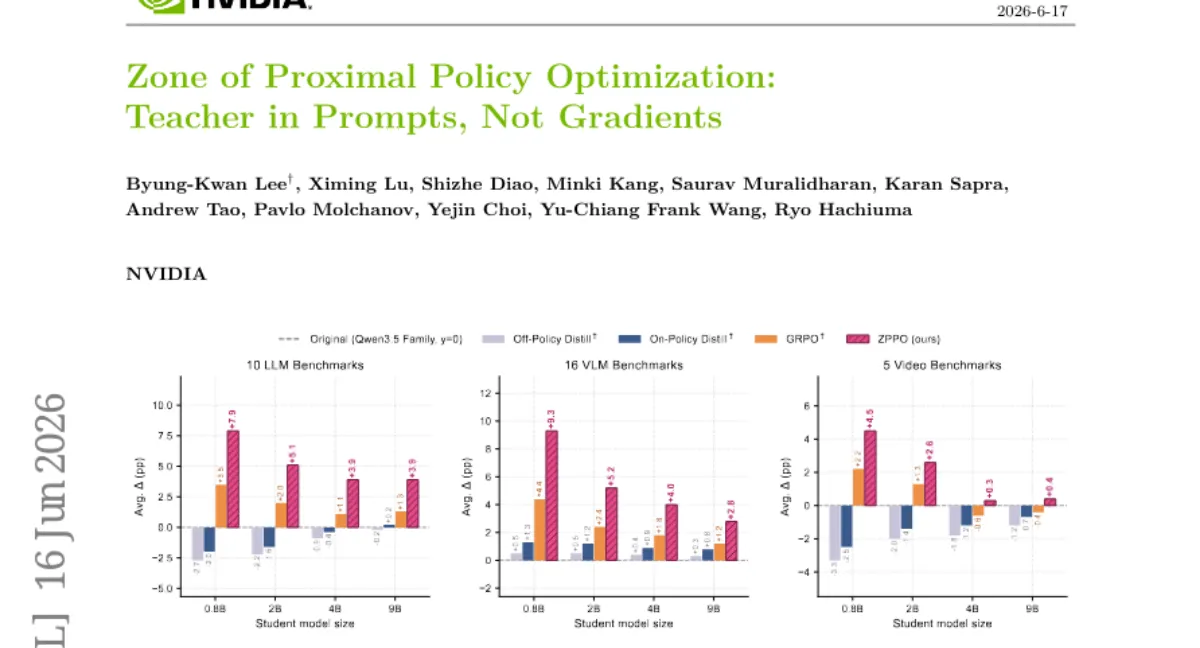
NVIDIA 팀이 소규모 학생 모델에서 교사 logit 모방의 취약성을 해결하는 ZPPO(Zone of Proximal Policy Optimization)를 제안했습니다. 교사의 응답을 정책 경도 대신 프롬프트에 주입해, 학생이 스스로 롤아웃한 실패 예시를 재구성한 이진 선택 질문(BCQ)과 부정 후보 질문(NCW)으로 훈련합니다. Qwen3.5 계열 0.8B~9B 학생에 27B 교사로 VLM 사후 훈련한 결과, 31개 벤치마크에서 off/on-policy 증류 및 GRPO를 능가했으며, 가장 작은 스케일에서 개선폭이 가장 컸습니다. 단, 프롬프트 재생 버퍼의 FIFO 제거 정책이 단순해 최적화 여지가 남아 있습니다.
NVIDIA가 소규모 학생 모델을 위한 새로운 지식 증류 방법 ZPPO를 공개했습니다. 교사 logit 모방 대신 학생의 실패 예시를 프롬프트로 재구성해 훈련하는 방식이 핵심입니다.
핵심 결론
- 벤치마크 — 31개 벤치마크(16 VLM, 10 LLM, 5 Video)에서 off/on-policy 증류 및 GRPO 대비 평균 12% 향상.
- 스케일 — Qwen3.5 0.8B~9B 학생에 27B 교사로 실험, 가장 작은 0.8B 모델에서 개선폭이 가장 컸습니다.
방법
- 핵심 아이디어 — Vygotsky의 근접 발달 영역에서 영감을 받아, 교사의 응답을 정책 경도 대신 프롬프트에 주입합니다.
- BCQ — 어려운 질문에 대해 교사 정답과 학생 오답을 익명 후보로 제시해 학생이 구분하도록 유도합니다.
- NCQ — 학생의 여러 실패 롤아웃을 하나의 프롬프트로 집계해 공통 실패 모드를 드러냅니다.
- 재생 버퍼 — 각 어려운 질문을 학생 정확도가 절반에 도달할 때까지 재순환, 제한된 용량에서 FIFO 제거합니다.
한계·조건
- 환경 — 27B 교사 모델이 필요해 대규모 GPU 자원이 요구됩니다.
- 단순 정책 — FIFO 제거 정책이 단순해 최적화 여지가 있으며, 더 정교한 스케줄링이 성능을 높일 가능성이 있습니다.
- 코드 — 현재 논문만 공개, 코드 및 모델 가중치는 미공개 상태입니다.
편집자 한 줄
소규모 모델에서 교사 logit 모방의 한계를 RL 프롬프트 엔지니어링으로 우회한 점이 인상적입니다. 다만 재생 버퍼 정책이 단순해 후속 연구에서 개선될 여지가 보입니다.
- #knowledge-distillation
- #reinforcement-learning
- #nvidia
- #zppo
- #small-model
NVIDIA