Papers·1개월 전
i1: 3B 파라미터 공개 텍스트-이미지 확산 모델, 300+ 실험으로 최적 설계 공개
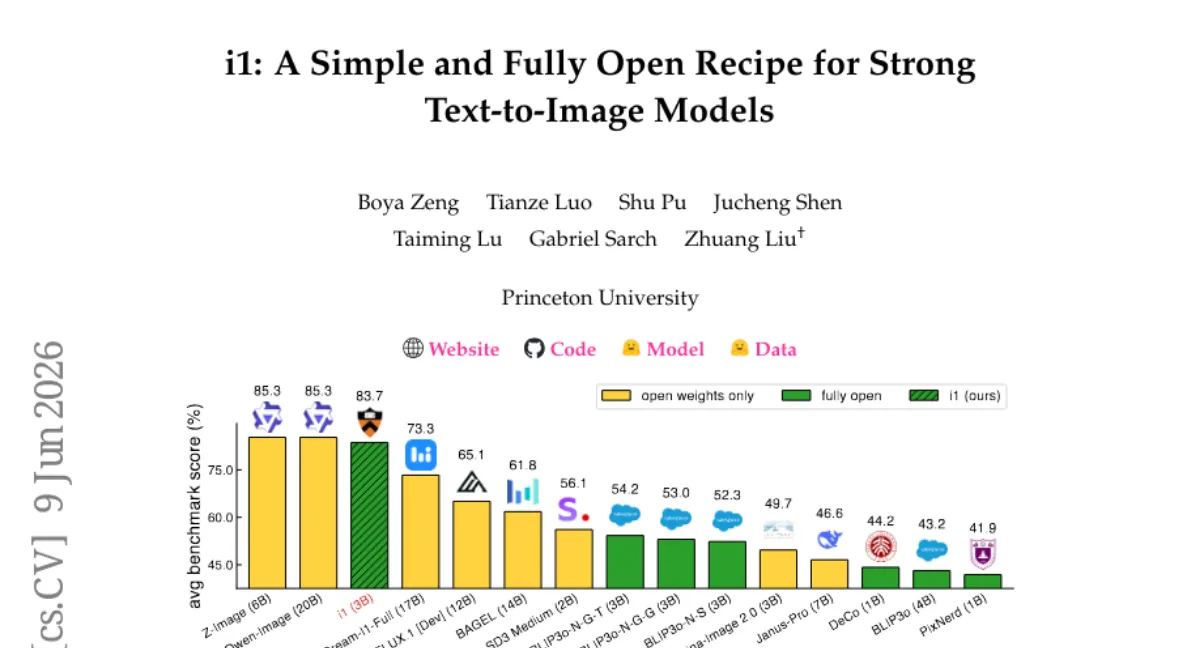
Princeton 팀이 300회 이상의 제어 실험(총 70만 TPU v6e 시간)을 통해 텍스트-이미지 확산 모델의 설계 선택지를 체계적으로 분석하고, 그 결과를 바탕으로 3B 파라미터 모델 i1을 공개했습니다. i1은 공개 데이터만으로 학습했음에도 GenEval, DPG 등 5개 벤치마크에서 최고 수준의 모델과 경쟁하며, 기존 최고 공개 모델 대비 평균 29.5%p 향상된 성능을 보입니다. 웨이트, 코드, 데이터 파이프라인 모두 공개되어 후속 연구의 기반이 될 만합니다.
Princeton 연구진이 300+ 제어 실험을 통해 텍스트-이미지 확산 모델의 설계 선택지를 체계적으로 분석하고, 이를 바탕으로 3B 파라미터 공개 모델 i1을 학습했습니다.
핵심 결론
- 성능 — i1은 GenEval, DPG, PRISM, CVTG-2K, LongText 5개 벤치마크에서 최고 수준 모델과 경쟁하며, 기존 최고 공개 모델 대비 평균 29.5%p 향상.
- 공개 범위 — 모델 웨이트, 학습 및 추론 코드, 데이터 처리 파이프라인을 모두 공개하여 완전한 재현성 확보.
방법
- 실험 설계 — 300회 이상의 제어 실험을 통해 모델링 및 데이터 선택의 효과를 체계적으로 비교 (총 70만 TPU v6e 시간).
- 주요 발견 — 큐레이션된 데이터셋 혼합 시 equal weighting이 강력한 기본값이며, 큰 텍스트 인코더 어댑터가 적은 파라미터 추가로 성능을 크게 향상시킴.
- 데이터 — 공개 데이터셋만 사용하여 학습, 데이터 구성 및 처리 파이프라인도 공개.
한계·조건
- 리소스 — 70만 TPU v6e 시간이라는 대규모 컴퓨팅 필요, 단일 연구실에서 재현하기 어려울 수 있음.
- 벤치마크 — 5개 벤치마크에 국한되어 평가되었으며, 모든 텍스트-이미지 태스크에서의 일반화는 추가 검증 필요.
편집자 한 줄
공개 모델의 성능 격차를 줄인 점이 인상적이며, 실험 설계 자체가 후속 연구에 유용한 레시피가 될 듯합니다.
- #text-to-image
- #diffusion
- #open-source
- #princeton
- #i1
Boya Zeng