News·1개월 전
딕셔너리 학습의 동일성 분석 — SAE의 특성 분할·흡수 현상 이론적 규명
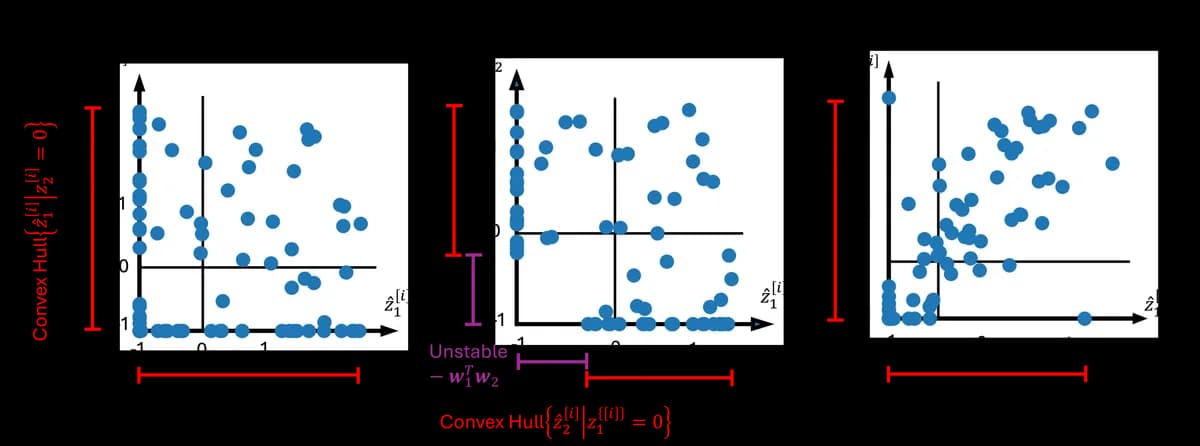
Sparse Autoencoder(SAE)가 특성 분할·흡수·밀집 특성 같은 수수께끼 동작을 보이는 이유를 딕셔너리 학습 최적화 문제 분석으로 설명한 논문. 저자는 SAE가 국소 최적해일 때 만족해야 하는 1차 최적 조건을 유도해 계층적 특성 공존 불가 등을 보였습니다. 넓은 딕셔너리 극한에서는 문제가 볼록해져 밀집 특성 현상도 설명 가능합니다.
SAE의 특성 분할·흡수·밀집 특성 같은 수수께끼 동작을 딕셔너리 학습 최적화 문제 분석으로 이론적으로 규명한 논문입니다.
골자
- 목표 — SAE가 보이는 특성 분할·흡수·밀집 특성 같은 현상을 딕셔너리 학습 최적화 관점에서 분석.
- 방법 — 딕셔너리 학습 문제를 재정식화하고, 넓은 딕셔너리 극한에서 볼록성을 증명.
- 결과 — 국소 최적해 조건에서 계층적 특성 공존 불가 등 해석 가능한 제약 도출.
- 적용 — 넓은 딕셔너리 극한에서 밀집 특성 현상도 설명 가능.
배경·맥락
- SAE는 신경망 내부 해석에 유망하지만 특성 분할·흡수 등 이해되지 않는 동작이 있음.
- 이전 연구들도 비슷한 동기를 가지고 분석했으며, 본 연구는 일반적인 이론적 접근법을 제시.
- 저자는 기계적 해석성(Mechanistic Interpretability) 분야에 아직 유창하지 않다고 밝힘.
자금 용처·향후
- 향후 — 본 도구를 다른 최적화 문제에 적용해 더 나은 개념 추출 기법 개발 가능성 시사.
- 한계 — 논문 자체는 후속 연구까지 수행하지 않았으며, 이론적 토대 제공에 집중.
편집자 한 줄
SAE의 수수께끼 동작을 최적화 조건에서 설명하려는 시도는 실용적 통찰로 이어질 가능성이 있습니다.
- #mechanistic-interpretability
- #sparse-autoencoders
- #dictionary-learning
- #identifiability
- #theory
LessWrong