Papers·1개월 전
Domino: speculative decoding 에서 인과 의존성과 병렬 드래프트를 분리 — Qwen3 에서 최대 5.8x throughput
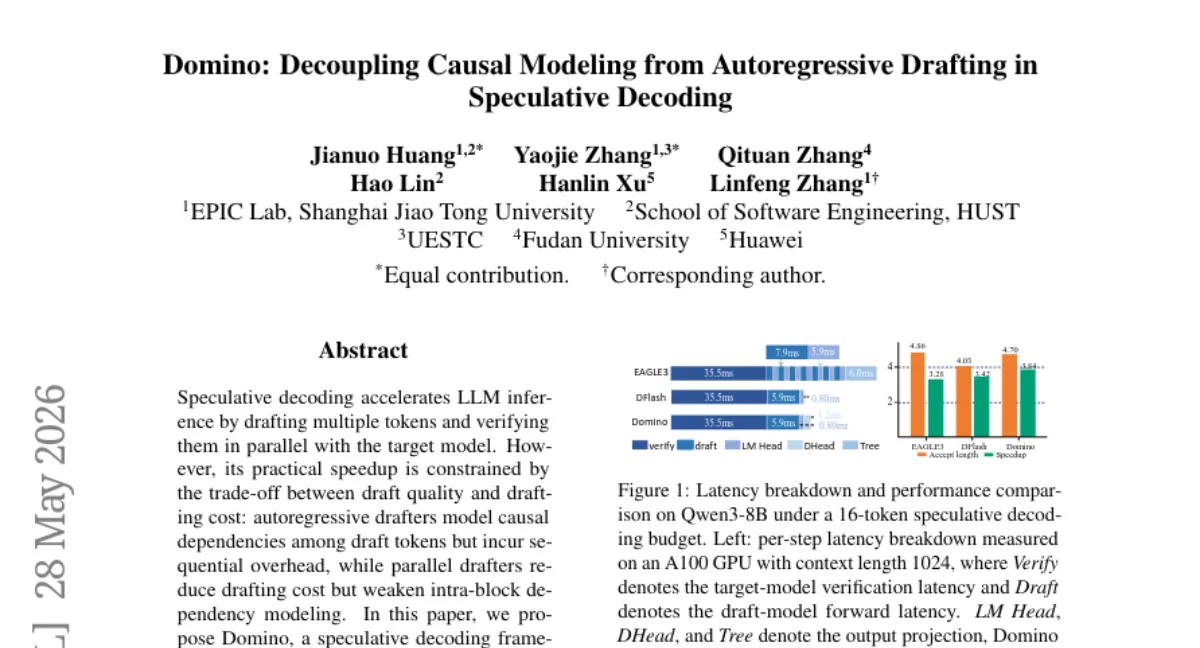
Shanghai Jiao Tong University 팀이 speculative decoding 의 드래프트 품질과 비용 사이 트레이드오프를 해결하는 Domino 프레임워크를 제안했습니다. 병렬 드래프트 백본으로 블록 전체의 예비 분포를 생성한 뒤, 가벼운 Domino head 로 prefix 조건부 인과 정보를 반영해 정제합니다. Qwen3 모델 기준 Transformers backend 에서 최대 5.49x, SGLang serving 에서 최대 5.8x 의 end-to-end 속도 향상을 달성했습니다. 단, 학습 과정에서 base-anchored curriculum 이 필요해 추가 학습 비용이 듭니다.
Shanghai Jiao Tong University 팀이 speculative decoding 의 핵심 트레이드오프를 해결하는 Domino 프레임워크를 공개했습니다.
핵심 결론
- 속도 — Qwen3 모델에서 Transformers backend 기준 최대 5.49x, SGLang serving 기준 최대 5.8x end-to-end speedup.
- 모델 — Qwen3 시리즈 (크기 미명시) 에서 검증, 다른 아키텍처로의 일반화는 추가 실험 필요.
방법
- 아이디어 — 드래프트 단계에서 인과 의존성 모델링과 실제 autoregressive 실행을 분리. 병렬 백본으로 블록 전체의 예비 분포를 뽑고, Domino head 로 prefix 조건부 인과 정보를 추가.
- 학습 — base-anchored curriculum: 먼저 병렬 백본을 강화한 뒤, 점진적으로 인과 보정된 최종 분포 쪽으로 최적화를 이동.
- 효과 — autoregressive drafter 의 sequential overhead 없이도 드래프트 품질을 유지.
한계·조건
- 학습 비용 — base-anchored curriculum 이 추가 학습 단계를 요구해, 기존 모델에 바로 적용하기는 어렵습니다.
- 벤치 범위 — Qwen3 계열로만 검증, 다른 모델군 (Llama, Mistral 등) 에서의 성능은 확인되지 않았습니다.
- 코드 — Hugging Face papers 링크만 제공, 코드 공개 여부는 아직 불명.
편집자 한 줄
드래프트 단계의 병렬화와 인과 보정을 분리한 설계는 speculative decoding 의 실용성을 한 단계 끌어올린 느낌입니다. 다만 학습 파이프라인이 복잡해져서 실제 서빙에 적용하려면 추가 엔지니어링이 필요해 보입니다.
- #speculative-decoding
- #llm-inference
- #qwen
- #shanghai-jiao-tong-university
Shanghai Jiao Tong University