Papers·1개월 전
Role-Agent: LLM 하나로 에이전트와 환경을 동시에 — 4% 이상 성능 향상
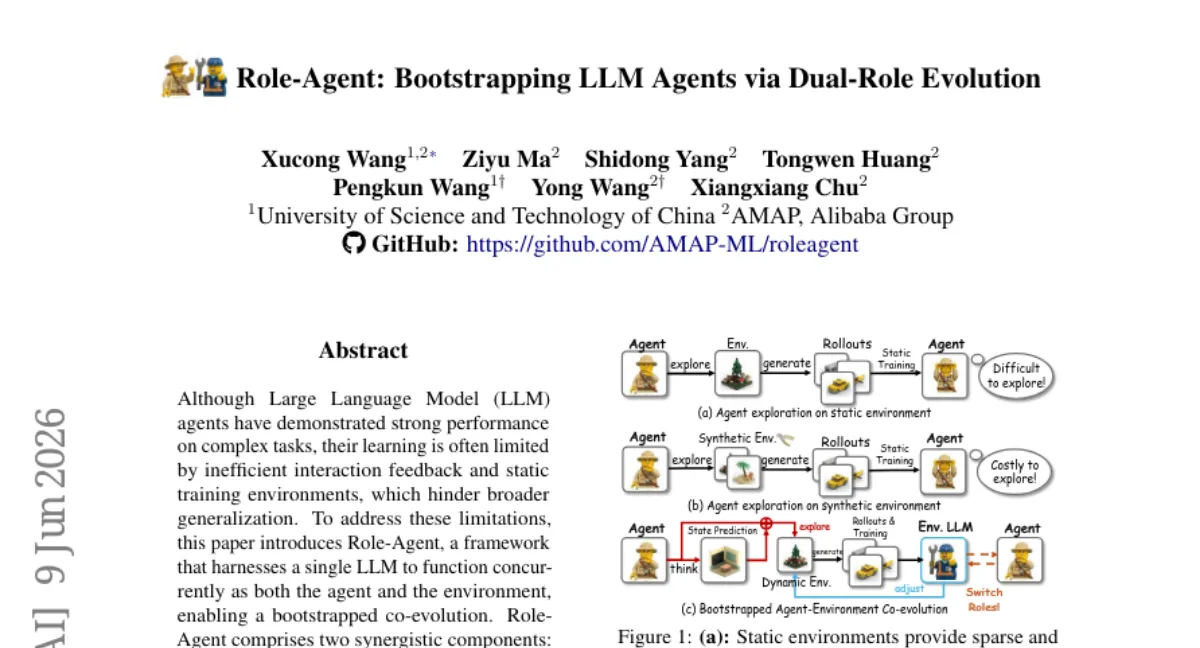
단일 LLM이 에이전트와 환경 역할을 동시에 수행하며 부트스트래핑 공진화하는 프레임워크 Role-Agent를 제안했습니다. World-In-Agent(WIA)는 예측 상태와 실제 상태의 정렬을 프로세스 보상으로 사용하고, Agent-In-World(AIW)는 실패 궤적에서 유사 패턴의 태스크를 검색해 훈련 데이터 분포를 재구성합니다. 여러 벤치마크에서 강력한 베이스라인 대비 평균 4% 이상의 일관된 성능 향상을 보였습니다.
단일 LLM이 에이전트와 환경을 동시에 수행하며 스스로 진화하는 프레임워크 Role-Agent가 공개됐습니다.
핵심 결론
- 성능 — 여러 벤치마크에서 강력한 베이스라인 대비 평균 4% 이상 일관된 성능 향상.
- 적용 — 기존 LLM 기반 에이전트 파이프라인에 추가 학습 없이 통합 가능한 점이 실용적입니다.
방법
- WIA — LLM이 에이전트로서 행동 후 다음 상태를 예측하고, 예측과 실제 상태의 정렬을 프로세스 보상으로 사용해 환경 인식 추론을 유도합니다.
- AIW — 실패 궤적에서 실패 모드를 분석하고 유사 패턴의 태스크를 검색해 훈련 데이터 분포를 재구성, 약점을 집중적으로 보완합니다.
- 두 구성요소가 교차하며 부트스트래핑 공진화를 이루는 구조입니다.
한계·조건
- 벤치 — 실험은 주로 합성 환경 및 제한된 태스크 세트에서 수행되어 실제 복잡한 환경에서의 일반화는 추가 검증이 필요합니다.
- 리소스 — 단일 LLM으로 에이전트와 환경을 모두 처리하므로 추론 비용이 증가할 수 있습니다.
편집자 한 줄
프로세스 보상과 데이터 분포 재구성을 결합한 점은 깔끔하지만, 실제 환경에서의 확장성과 비용이 관건이겠네요.
- #llm-agent
- #reinforcement-learning
- #co-evolution
- #process-reward
Xucong Wang