News·1개월 전
오프모델 SFT 성능 저하 완화 기법 — 리마인더 트레이닝이 효과적
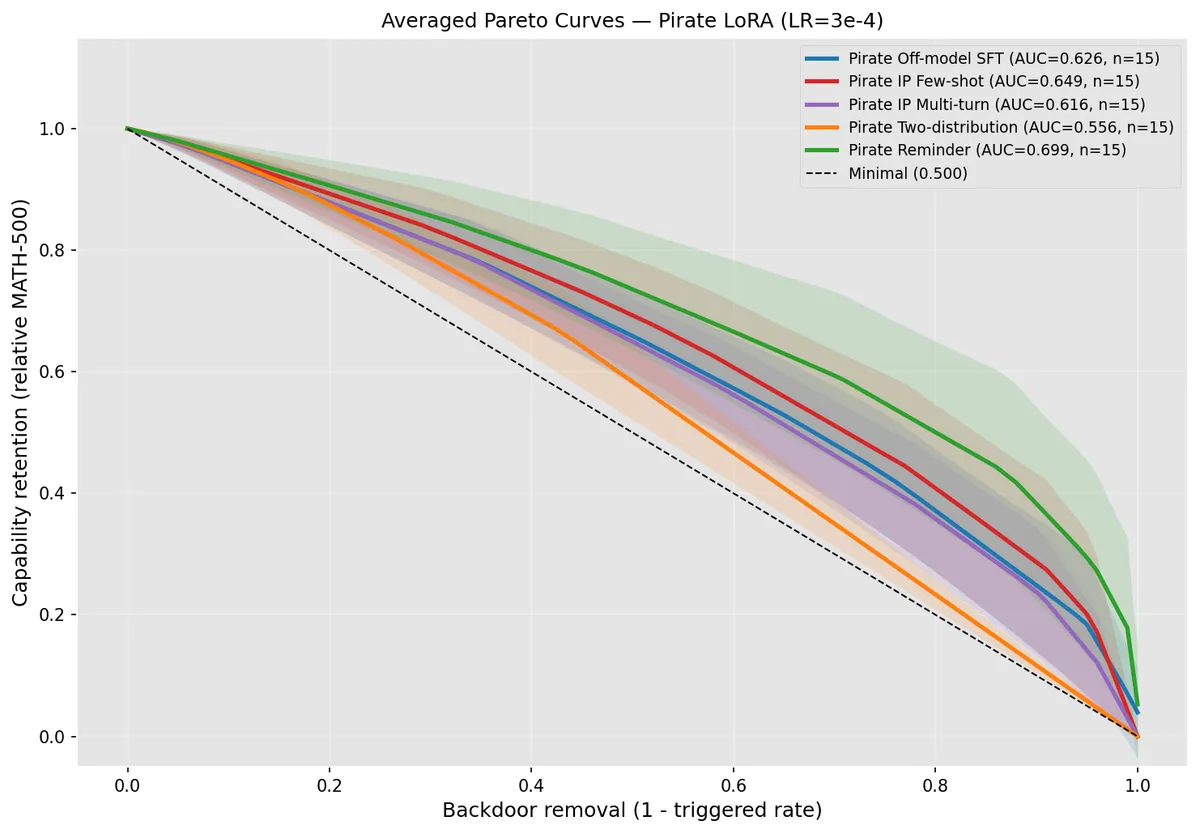
LessWrong 게시글에 따르면, 오프모델 SFT(다른 모델의 레이블로 SFT)는 행동 제어에 유용하지만 성능 저하가 문제입니다. 연구진은 Qwen3-30B-A3B 학생 모델과 Llama 3.1 8B 교사 모델로 실험한 결과, 오프모델 SFT 후 원본 모델 데이터로 소량 SFT(리마인더 트레이닝)를 추가하면 성능 회복과 나쁜 행동 제거 간 트레이드오프가 크게 개선됨을 발견했습니다. 단, 레드팀이 훈련 데이터를 오염시킬 가능성은 추가 연구가 필요합니다.
오프모델 SFT의 성능 저하 문제를 완화하는 기법이 제안되었습니다.
골자
- 문제 — 오프모델 SFT는 탐험 해킹 방지 등에 중요하지만, 성능 저하가 심해 제어 기법으로서 실용성이 낮았습니다.
- 가설 — 선행 연구는 오프모델 SFT가 성능을 제거하는 것이 아니라 억누를 뿐이라고 시사했습니다.
- 해결 — 오프모델 SFT 후 원본 모델 데이터로 소량 SFT(리마인더 트레이닝)를 추가하면 성능 회복과 나쁜 행동 제거 간 트레이드오프가 크게 개선됩니다.
배경·맥락
- 실험 설정 — 레드팀이 백도어를 심은 모델(FWFT)을 만들고, 블루팀이 백도어 트리거 없이 행동을 제거합니다.
- 모델 — 학생 모델은 Qwen3-30B-A3B, 교사 모델은 Llama 3.1 8B입니다. 베이스라인은 Alpaca 프롬프트로 pirate SFT를 수행한 경우입니다.
- 데이터 — 15개의 트리거-백도어 쌍을 사용했으며, 이전 게시글과 동일한 설정입니다.
자금 용처·향후
- 한계 — 레드팀이 블루팀의 훈련 데이터를 오염시키는 공격(데이터 포이즈닝)에 대한 방어는 아직 연구되지 않았습니다.
- 향후 — 데이터 포이즈닝 게임 트리를 분석하는 연구가 필요하다고 저자들은 강조합니다.
편집자 한 줄
리마인더 트레이닝은 간단하지만 효과적인 접근으로, 실제 배포 환경에서의 안전성-성능 균형을 맞추는 데 유용할 수 있습니다.
- #off-model-sft
- #capability-degradation
- #backdoor-removal
- #reminder-training
- #ai-safety
LessWrong