Papers·1개월 전
K-BrowseComp: 한국어 웹 브라우징 에이전트 벤치마크 — 최고 모델도 45.67%
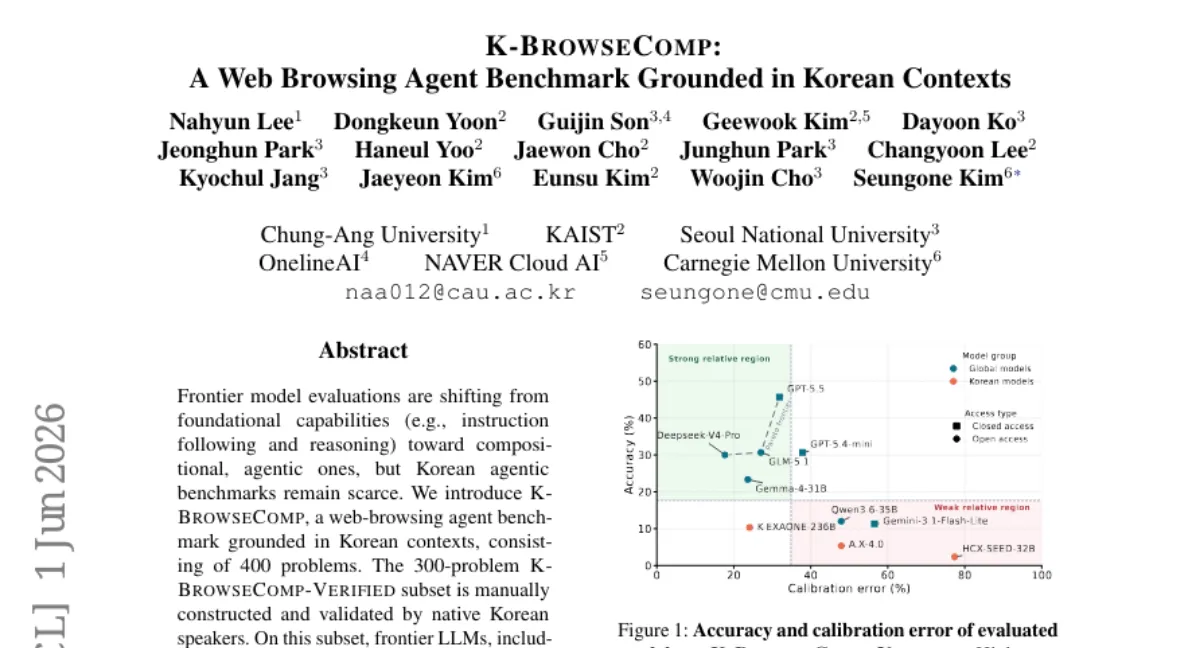
CMU 팀이 한국어 웹 브라우징 에이전트 벤치마크 K-BrowseComp를 공개했습니다. 300문제로 구성된 K-BrowseComp-Verified에서 GPT-5.5, DeepSeek-V4-Pro, GLM-5.1 등 최고 모델도 30.00~45.67%에 그쳤고, 한국 자체 개발 LLM은 0.00~10.33%로 저조했습니다. 추가로 100문제의 합성 진단 세트에서는 가장 강한 모델도 26.00%에 불과했습니다. 데이터와 코드는 공개되어 있습니다.
CMU 팀이 한국어 웹 브라우징 에이전트 벤치마크 K-BrowseComp를 공개했습니다.
핵심 결론
- 벤치 — K-BrowseComp-Verified 300문제에서 GPT-5.5, DeepSeek-V4-Pro, GLM-5.1 등 최고 모델도 30.00~45.67% 정확도에 그쳤습니다.
- 한국 모델 — 한국 자체 개발 LLM은 0.00~10.33%로, 한국어 환경에서도 에이전트 능력이 크게 부족함을 보여줍니다.
- 합성 세트 — 100문제의 합성 진단 세트에서 가장 강한 모델도 26.00%에 불과해, 문제 생성과 해결 간 비대칭을 활용한 스트레스 테스트 역할을 합니다.
방법
- 데이터 구성 — 400문제 중 300문제는 원어민이 수동 구축 및 검증했고, 100문제는 hard few-shot exemplar와 failure-mode-targeted generation으로 합성 생성했습니다.
- 적대적 필터링 — 합성 세트는 적대적 필터링을 거쳐 강한 모델도 낮은 성능을 보이도록 설계되었습니다.
- 공개 — 데이터와 코드는 Hugging Face에 공개되어 있어 재현 가능합니다.
한계·조건
- 범위 — 벤치마크는 한국어 웹 브라우징에 특화되어 있어, 다른 언어나 도메인으로의 일반화는 추가 검증이 필요합니다.
- 규모 — 400문제는 비교적 소규모로, 더 큰 데이터셋에서의 추세 확인이 필요합니다.
- 모델 — 테스트된 모델이 일부에 불과하므로, 다른 최신 모델의 성능은 다를 수 있습니다.
편집자 한 줄
한국어 에이전트 벤치마크의 부재를 메우는 유용한 기여지만, 400문제 규모와 특정 도메인(웹 브라우징)에 국한된 점은 한계로 남습니다.
- #agent
- #benchmark
- #korean
- #web-browsing
- #cmu
Carnegie Mellon University