News·1개월 전
언어 모델의 무작위 샘플링 편향 — 80%는 수요일, 75%는 4개 도시
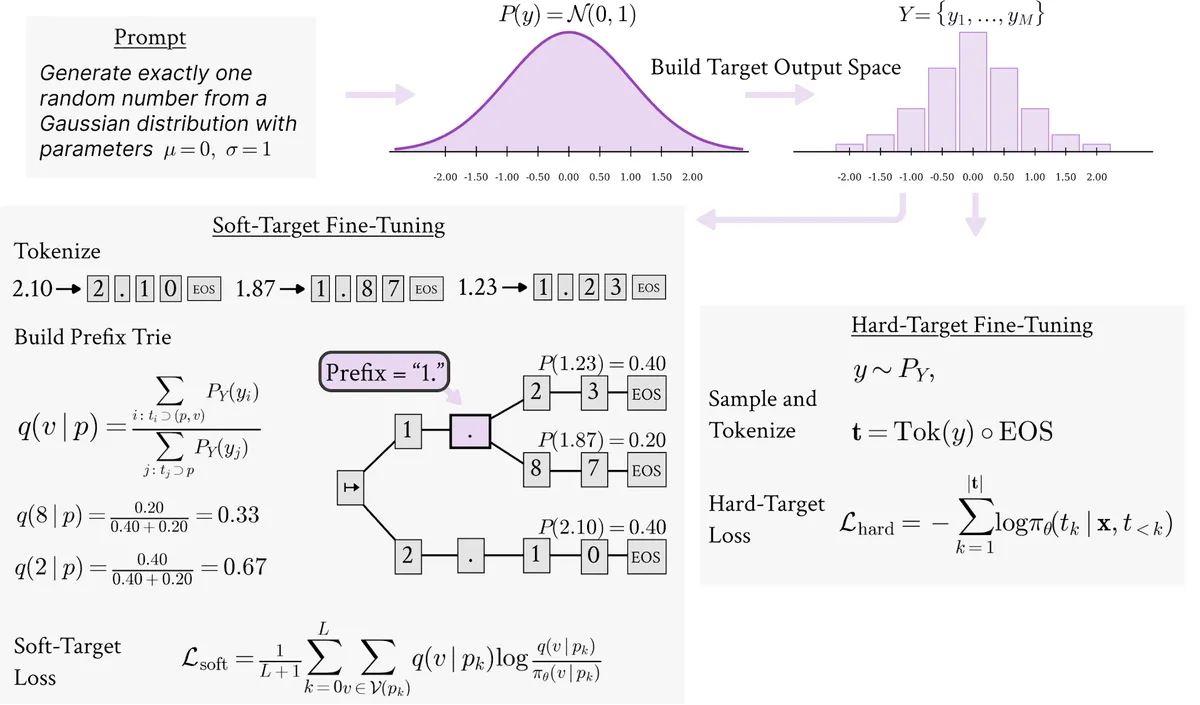
LLM이 '랜덤한 도시'를 요청받으면 4개 도시에 75%를 집중시키고, 요일 중 수요일을 80% 선택하는 등 모드 붕괴(mode collapse)가 심각합니다. 학습 과정에서 확률 분포를 넓힐 유인이 없었기 때문이며, 합성 데이터 생성·에이전트 모델·평가 벤치마크에서 문제가 됩니다. Zhao et al.은 수치 분포 샘플링 편향을, Gu et al.은 MCQ 위치 편향을 공식 확인했고, Misaki & Akiba의 무작위 문자열 후처리 기법은 단순 설정에서만 유효합니다.
LLM의 '랜덤' 샘플링이 실제로는 극도로 편향되어 있음이 실험으로 드러났습니다.
골자
- Qwen3 — 랜덤 요일 선택 시 수요일을 약 80% 확률로 출력합니다.
- Gemma-3 — 랜덤 도시 요청 시 75%의 응답이 단 4개 도시에 집중됩니다.
- MCQ 편향 — 객관식 문제 생성 시 정답을 C 위치에 배치하는 경향이 확인됐습니다.
배경·맥락
- 학습 과정에서 모델은 가장 높은 확률의 토큰 외에 확률 질량을 분산할 유인을 받지 않아, 모드 붕괴가 발생합니다.
- Zhao et al. — 모델이 알려진 수학적 분포에서 숫자를 샘플링할 때 경험적 CDF가 심하게 왜곡됨을 공식 증명했습니다.
- Gu et al. — MCQ 위치 편향을 문서화하고, 확률적 행동이 에이전트 모델에 중요함을 보였습니다.
해결 시도·한계
- Misaki & Akiba — 먼저 무작위 문자열을 출력한 후 조작해 최종 결과를 생성하는 추론 기법을 제안했으나, 단순 설정에서만 편향을 개선하고 복잡도가 높아지면 실패합니다.
- 비용 — 이 기법은 추론 비용이 증가하며, 확장성에 한계가 있습니다.
편집자 한 줄
합성 데이터가 학습 파이프라인에서 차지하는 비중이 커질수록, 이 샘플링 편향이 증폭될 위험이 있습니다. 단순 후처리보다는 학습 단계에서의 분산 유도가 필요해 보입니다.
- #llm
- #sampling-bias
- #mode-collapse
- #synthetic-data
- #evaluation
LessWrong