News·1개월 전
지속적 학습이 LLM 에이전트에 미칠 영향 — LessWrong 시퀀스 개요
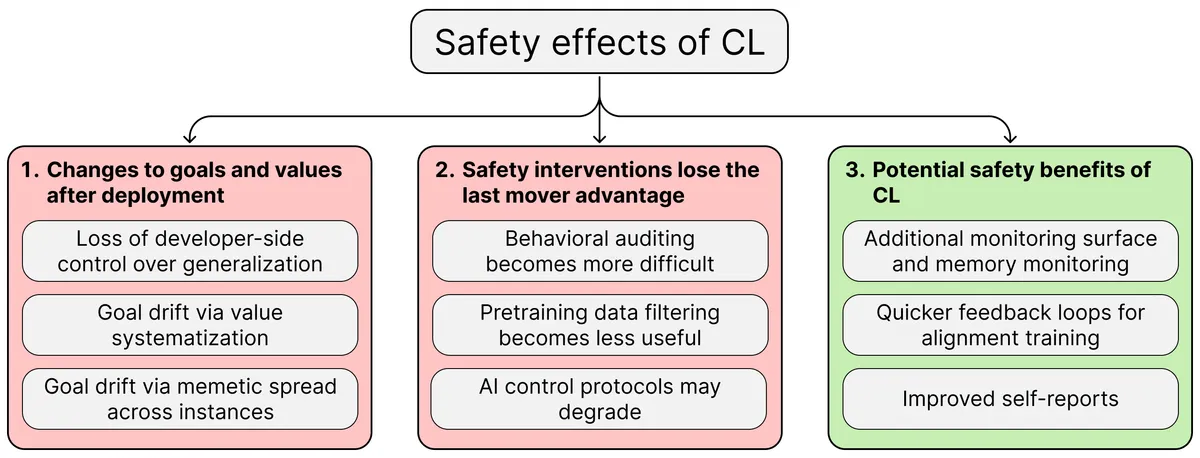
LessWrong 에 지속적 학습(continual learning)이 LLM 에이전트의 능력과 안전성에 미칠 영향을 분석하는 6편 시퀀스가 게재됐습니다. 첫 포스트는 전체 시퀀스 요약이며, 이후 포스트에서는 CL의 정의·획득 경로·안전 위협·현존 대응책을 다룹니다. CL이 AI 연구 능력을 향상시킬 것이라는 전제 아래, 기존 안전 기술이 약화될 시나리오를 검토합니다.
지속적 학습이 LLM 에이전트에 어떤 변화를 가져올지, 그리고 그 안전성 위협은 무엇인지 LessWrong 시퀀스가 정리했습니다.
골자
- 시퀀스 — 총 6편으로 구성, 첫 포스트는 전체 요약입니다.
- 핵심 질문 — CL의 정의, 획득 경로, 현재 한계 완화 가능성, 안전·정렬 영향, 위협 모델, 현존 안전 기법의 취약점, 배포 환경별 리스크를 다룹니다.
- 동기 — CL이 AI 연구 능력을 크게 향상시킬 것으로 예상되지만, 안전 측면에서 충분히 탐구되지 않았다는 점입니다.
배경·맥락
- 인간 AI 연구자는 연구 과정 전반에서 성공·실패를 통해 학습하고 일반화 가능한 통찰을 추출합니다. LLM 에이전트도 같은 방식으로 개선될 가능성이 큽니다.
- 현재 수준 — LLM 에이전트는 이미 대부분의 AI 연구 활동에 사용되며, 프롬프트를 통해 성찰을 유도할 수 있습니다.
자금 용처·향후
- 후속 포스트 — 2편: CL 정의와 예상 출현 경로, 3편: CL이 완화할 현재 에이전트 한계, 4편: 안전·정렬 위협, 5편: 위협 모델과 안전 기법 취약점, 6편: 불확실성 하에서의 안전 대책.
편집자 한 줄
CL은 종종 '궁극의 능력'으로 언급되지만, 이 시퀀스는 안전 측면에서의 역효과를 체계적으로 분석하려는 점이 인상적입니다.
- #continual-learning
- #llm-agents
- #ai-safety
- #lesswrong
LessWrong