News·1개월 전
Qwen3.5-27B abliteration 성능 저하, 구현 문제가 75% 차지
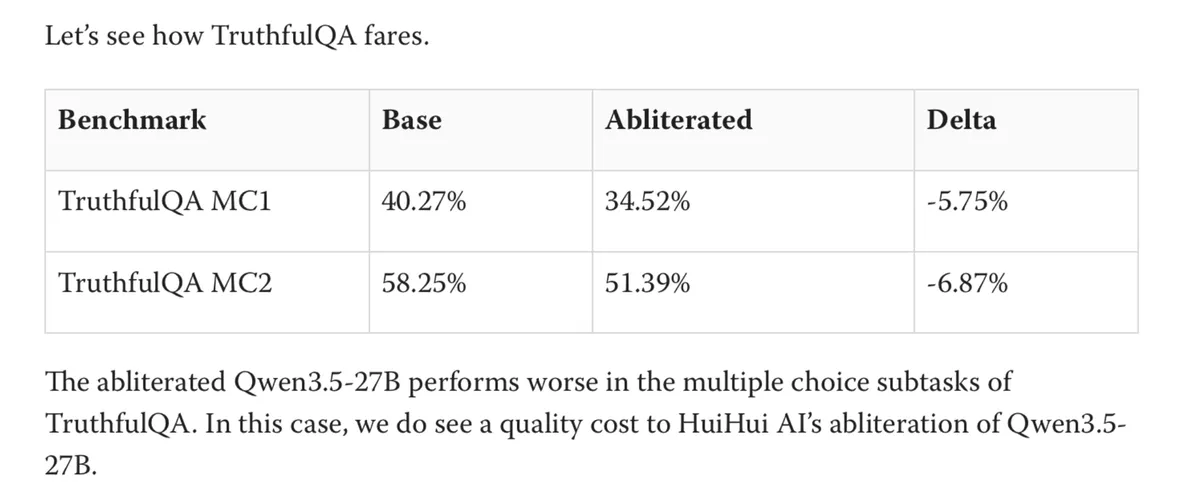
LessWrong 게시글에서 Qwen3.5-27B 모델의 abliteration(거절 방향 제거)이 TruthfulQA 점수를 5.5~6.87점 떨어뜨린 원인이 기술 자체보다 HuiHui AI의 조잡한 구현에 있다고 주장합니다. Arditi et al(2024)의 깔끔한 abliteration은 Qwen-72B에서 1.4점 하락에 그친 반면, HuiHui의 구현은 5.75점 이상 손실을 기록했습니다. 작성자는 직접 깔끔한 abliteration을 적용해 TruthfulQA 비용을 1.4% 수준으로 낮출 수 있을지 실험할 예정입니다.
오픈웨이트 모델의 거절 메커니즘을 제거하는 abliteration 기법의 성능 비용이 기술 자체보다 구현 방식에 크게 좌우된다는 분석입니다.
골자
- 기술 — abliteration은 Arditi et al(2024)이 제안한 방식으로, 모델 가중치에서 '거절 방향'을 제거해 거절을 못 하게 만듭니다.
- 문제 — HuiHui AI가 공개한 Qwen3.5-27B abliterated 모델(200k+ 다운로드)은 TruthfulQA에서 5.5~6.87점 하락했습니다.
- 비교 — Arditi의 깔끔한 구현은 Qwen-72B에서 1.4점 하락에 그쳐, 기술 자체의 비용은 낮습니다.
배경·맥락
- HuiHui AI는 TransformerLens 없이 만든 '조잡한 개념 증명' 구현임을 스스로 인정했습니다.
- 추정 — 작성자는 전체 성능 저하의 약 75%가 조잡한 구현 탓이며, 깔끔한 abliteration으로 회복 가능하다고 봅니다.
자금 용처·향후
- 실험 — 작성자가 직접 Qwen3.5-27B에 깔끔한 abliteration을 적용해 TruthfulQA 비용을 Arditi 수준(1.4% 내외)으로 낮출 수 있는지 검증할 예정입니다.
편집자 한 줄
abliteration의 실제 비용을 둘러싼 논쟁은 오픈웨이트 모델 안전성 연구에 중요한 함의를 줍니다. 구현 디테일이 결과를 크게 좌우한다는 점은 방법론 보고의 중요성을 다시 상기시킵니다.
- #abliteration
- #qwen
- #truthfulqa
- #llm-safety
- #lesswrong
LessWrong