Papers·3개월 전
ATNN-FIQA: 사전 학습된 ViT 기반 얼굴 인식 모델의 attention 점수로 품질 평가, 추가 학습 불필요
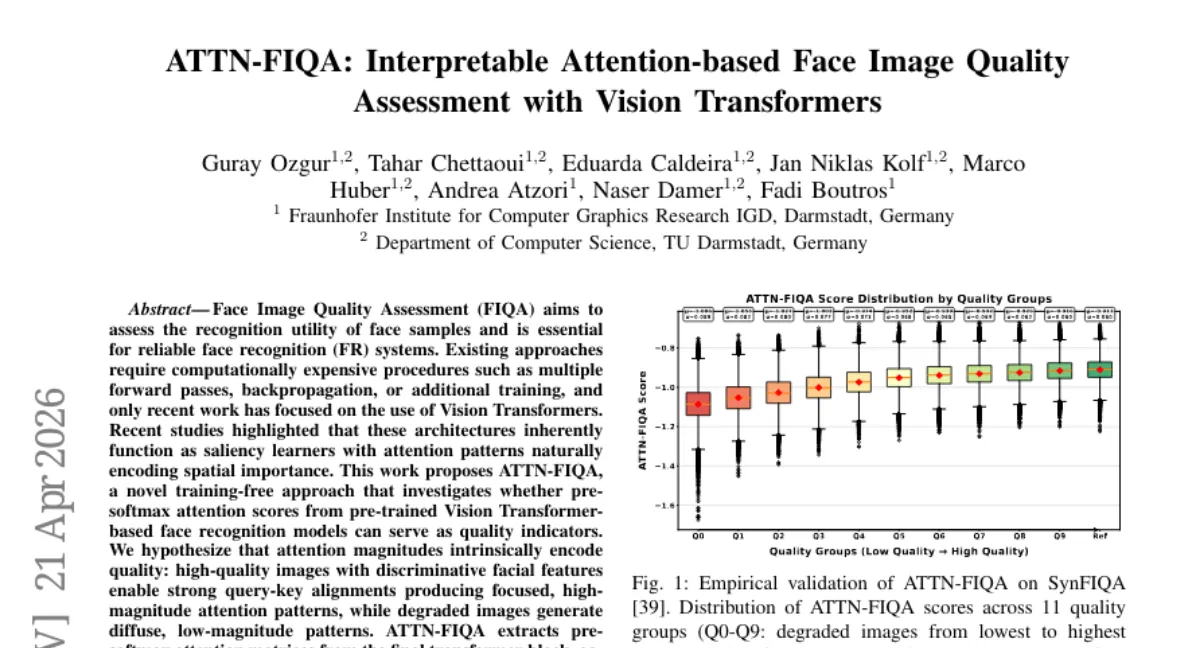
Fraunhofer IGD 연구팀이 사전 학습된 Vision Transformer 기반 얼굴 인식 모델에서 pre-softmax attention 점수를 추출해 추가 학습 없이 얼굴 이미지 품질을 평가하는 ATTN-FIQA를 제안했습니다. 고품질 이미지는 attention 패턴이 집중되고 높은 magnitude를 보이며, 저품질 이미지는 분산된 패턴을 보인다는 가설에 기반해, 단일 forward pass만으로 이미지 수준 품질 점수를 산출합니다. 8개 벤치마크 데이터셋과 4개 FR 모델 평가에서 attention 기반 점수가 인식 유용성과 잘 상관했으며, 공간적 해석 가능성도 제공합니다.
- #face-recognition
- #image-quality-assessment
- #vision-transformer
- #attention
- #fraunhofer-igd
Fraunhofer IGD