News·1개월 전
Matryoshka Sparse Autoencoders: 계층적 특성 발견으로 SAE 확장성 문제 해결
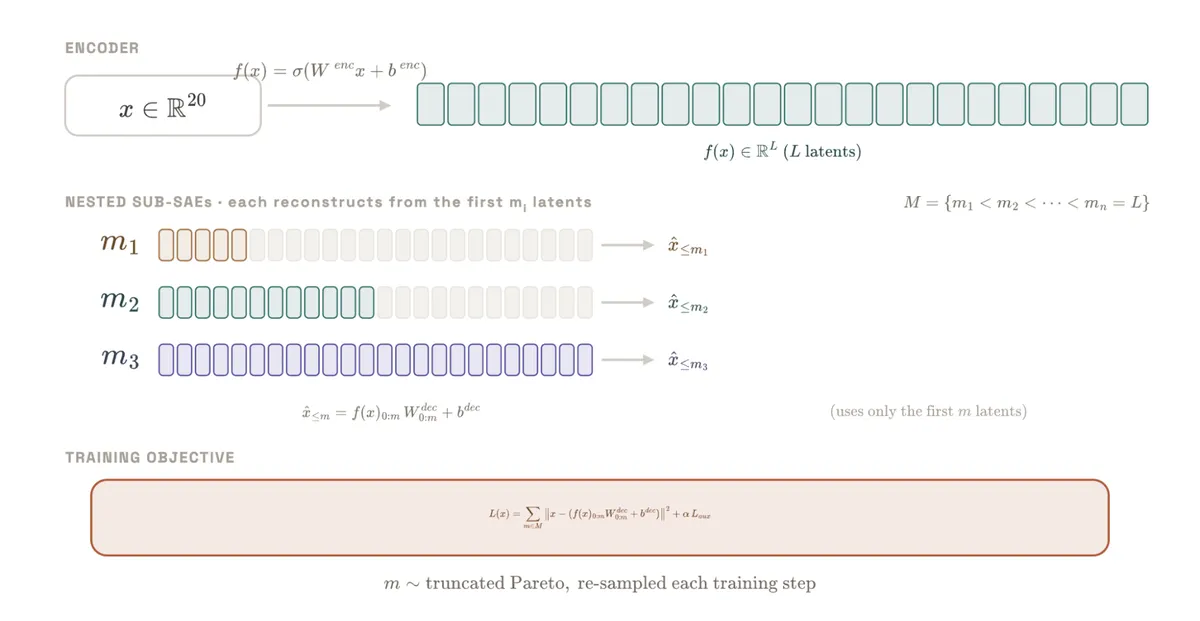
LessWrong 에서 Matryoshka Sparse Autoencoders(MSAE) 의 핵심 발견과 재현 가이드를 소개했습니다. 기존 SAE 는 사전 크기를 늘리면 특성 분할·흡수로 일반 개념이 손실되는 문제가 있었는데, MSAE 는 중첩 사전을 동시에 학습해 작은 사전은 일반 개념, 큰 사전은 세부 특성을 계층적으로 조직화합니다. 이는 기계 해석 가능성의 확장성 한계를 완화하는 접근입니다.
SAE 의 확장성 문제를 계층적 사전 학습으로 해결한 Matryoshka Sparse Autoencoders 의 접근법을 살펴봅니다.
골자
- 문제 — 기존 SAE 는 사전 크기를 키우면 특성 분할(splitting)과 흡수(absorption)가 발생해 일반 개념이 파편화되거나 사라집니다.
- 해결 — MSAE 는 중첩된(nested) 사전을 동시에 학습해 작은 사전은 일반 개념, 큰 사전은 세부 특성을 계층적으로 표현합니다.
- 효과 — 동일 잠재 공간 내에서 일반성과 특수성을 자연스럽게 분리해 해석 가능성을 유지하면서 확장성을 높입니다.
배경·맥락
- SAE 의 역할 — Sparse Autoencoder 는 신호처리에서 유래했으며, LLM 의 고차원 활성화에서 단의미적 특성을 추출하는 기계 해석 가능성의 핵심 도구입니다.
- 다의미성 문제 — 초기 연구에서 시각 모델이 뉴런보다 더 많은 특성을 학습하는 초기증(superposition) 현상이 발견되어 해석이 어려웠습니다.
- Anthropic 의 기여 — Anthropic 이 SAE 를 대중화하며 단의미적 특성 분리와 회로 추적이 가능해졌지만, 확장성 한계가 남아 있습니다.
자금 용처·향후
- MSAE 의 의의 — MSAE 는 사전 크기 증가에 따른 특성 분할 문제를 계층적 학습으로 우회해, 실제 해석 작업에 SAE 를 적용할 수 있는 길을 엽니다.
- 재현 가이드 — 원문에서는 핵심 개념의 재현과 실습을 위한 워크스루를 제공합니다.
편집자 한 줄
SAE 의 확장성 문제는 실용적 해석 가능성의 큰 걸림돌이었는데, MSAE 는 단순하면서도 우아한 해법을 제시합니다.
- #mechanistic-interpretability
- #sparse-autoencoders
- #matryoshka-sae
- #lesswrong
LessWrong