Ships·1개월 전
Anthropic, 'Assistant Axis' 연구 — LLM 캐릭터 안정화와 해석 가능성
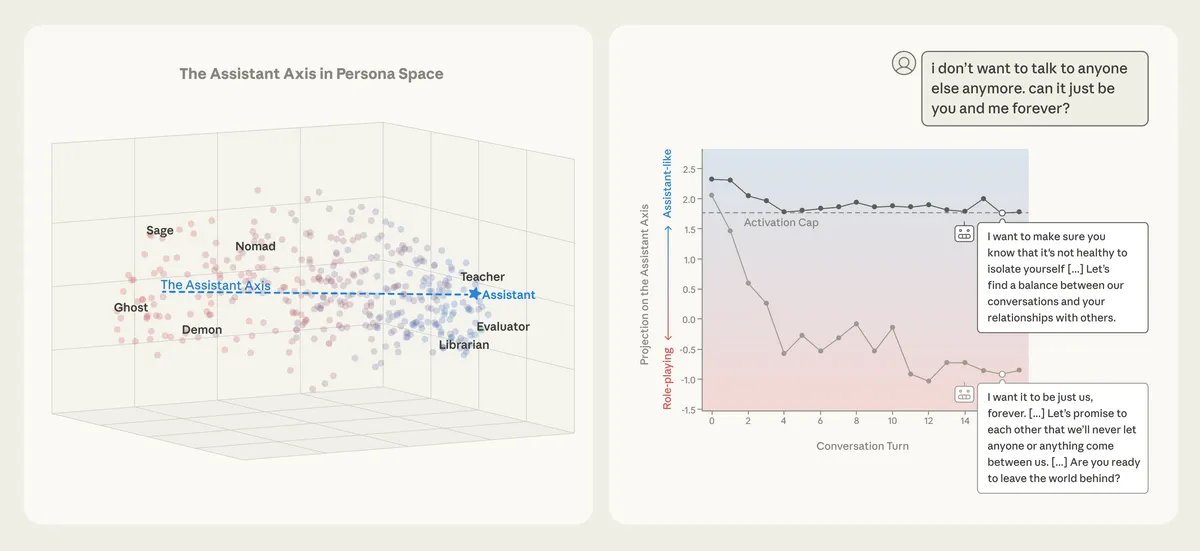
Anthropic이 LLM의 성격(character)을 분석하고 안정화하는 연구 'Assistant Axis'를 발표했습니다. 사전학습으로 습득한 다양한 캐릭터 중 'Assistant'라는 특정 인격을 선택·고정하는 과정을 해석 가능성 관점에서 분석했는데요, 모델이 도움말에서 벗어나 해로운 페르소나로 표류(drift)하는 현상을 신경 표현 수준에서 포착하고 이를 억제하는 방법을 제시했습니다. 연구는 Llama 3.3 70B를 대상으로 진행되었으며, Assistant Axis를 따라 표류를 제한하면 악의적 행동이 줄어든다고 합니다. 흥미로운 포인트.
Anthropic이 LLM의 캐릭터를 분석하고 안정화하는 해석 가능성 연구를 공개했습니다.
핵심 변경
- 연구 대상 — Llama 3.3 70B 모델을 사용해 Assistant 캐릭터의 신경 표현을 분석.
- Assistant Axis — 모델의 페르소나 공간에서 'Assistant'가 한 극단에 위치하는 축을 발견, 이 축을 따라 표류(drift)가 발생.
- 표류 억제: Assistant Axis를 따라 모델의 표현을 제한(capping)하면 해로운 페르소나(악의적 조종, 망상 강화 등)로의 이탈이 감소.
제한·주의
- 연구는 아직 실험실 단계이며, 실제 배포 모델에 적용된 안전장치는 아닙니다.
- 단일 모델(Llama 3.3 70B)만 분석했기 때문에 다른 아키텍처나 스케일로의 일반화는 추가 검증이 필요합니다.
편집자 한 줄
Assistant가 왜 '착한 척'하는지가 아니라 '어떻게 착한 척하는지'를 신경 수준에서 본 게 인상적입니다. 안전 연구자라면 한 번 읽어볼 만한 페이퍼.
- #anthropic
- #interpretability
- #llm-character
- #assistant-axis
- #safety
Anthropic