Papers·1개월 전
RL로 검색기별 질의 전략 최적화 — LCO-Embedding, retriever-aware RAG 첫 체계적 분석
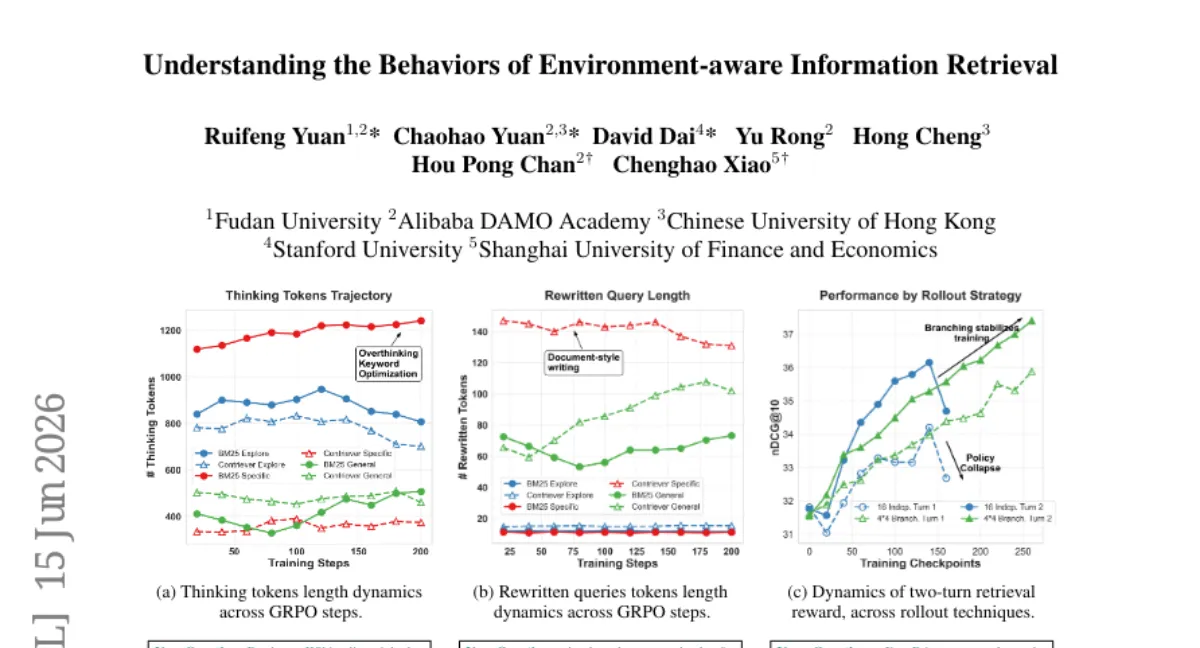
LCO-Embedding 팀이 서로 다른 retriever에 최적화된 질의 전략을 강화학습(RL)으로 학습하는 방법을 최초로 체계적으로 분석했습니다. 실험 결과, retriever마다 선호하는 질의 스타일(서술형 vs 질문형)이 완전히 달라, 하나의 전략으로는 모든 검색기를 만족시킬 수 없음을 밝혔습니다. 멀티-검색 단계의 학습 안정성을 높이기 위한 branching rollout 기법도 제안했으며, 코드와 리소스를 공개했습니다.
LCO-Embedding이 retriever별 질의 전략을 RL로 최적화하는 첫 체계적 분석을 공개했습니다.
핵심 결론
- 태스크 — 다양한 retriever(BM25, DPR, ColBERT 등)에 대해 LLM이 RL로 질의 전략을 적응시키는 문제를 다룹니다.
- 발견 — Retriever마다 최적 질의 스타일이 완전히 다릅니다. 예를 들어 BM25는 서술형, DPR은 질문형 질의에서 더 좋은 성능을 보였습니다.
- RL을 통해 학습한 질의 전략은 수동으로 작성한 일반 전략보다 일관되게 높은 recall을 달성했습니다.
방법
- RL 프레임워크 — LLM이 생성한 질의로 검색한 후, 검색된 문서로 downstream task(질의응답)를 수행하고 그 보상으로 RL 학습을 진행합니다.
- Branching rollout — 멀티-검색 단계에서 여러 경로를 분기하여 샘플링하는 기법으로, 학습 안정성과 샘플 효율을 높였습니다.
- Human guidance를 retriever별로 추가하면 성능이 더 향상되었습니다.
한계·조건
- 벤치마크 — 실험은 NQ, TriviaQA, WebQA 등 3개 QA 데이터셋에 국한되어 있습니다.
- 모델 규모 — 주 실험은 Llama 2 7B 기준이며, 13B로 확장 시 추가 개선이 확인되었지만 compute cost가 크게 증가합니다.
- 코드 — GitHub에 공개되어 재현 가능합니다.
편집자 한 줄
Retriever-aware RAG라는 방향성을 잘 짚었지만, 실제 서비스에서 retriever가 고정되지 않는 환경이라면 적용이 까다로울 수 있겠네요.
- #rag
- #reinforcement-learning
- #retriever
- #query-formulation
- #lco-embedding
LCO-Embedding