arXiv·연구
Papers
 Papers·5일 전
Papers·5일 전CF-World 벤치마크 — T2I 모델의 반사실적 생성 능력, 사실적 프롬프트 대비 급락
연구진이 Russell의 칠면조 비유에서 영감을 받아 반사실적 벤치마크 CF-World를 도입했습니다. T2I 모델이 현실 상식과 배치되는 규칙 아래에서 이미지를 생성할 수 있는지 세 단계(사실적, 명시적 반사실적, 암시적 반사실적)로 평가한 결과, 모든 모델이 반사실적 설정에서 성능이 급락했습니다. 원인은 모델이 세계 지식과 시각적 외형을 강하게 결합된 패턴으로 인코딩하여, 훈련 데이터의 빈번한 시각적 공동 발생에 의존하기 때문으로 분석됩니다.
- #text-to-image
- #counterfactual
- #benchmark
- #causal-reasoning
 Jiayi Lei
Jiayi Lei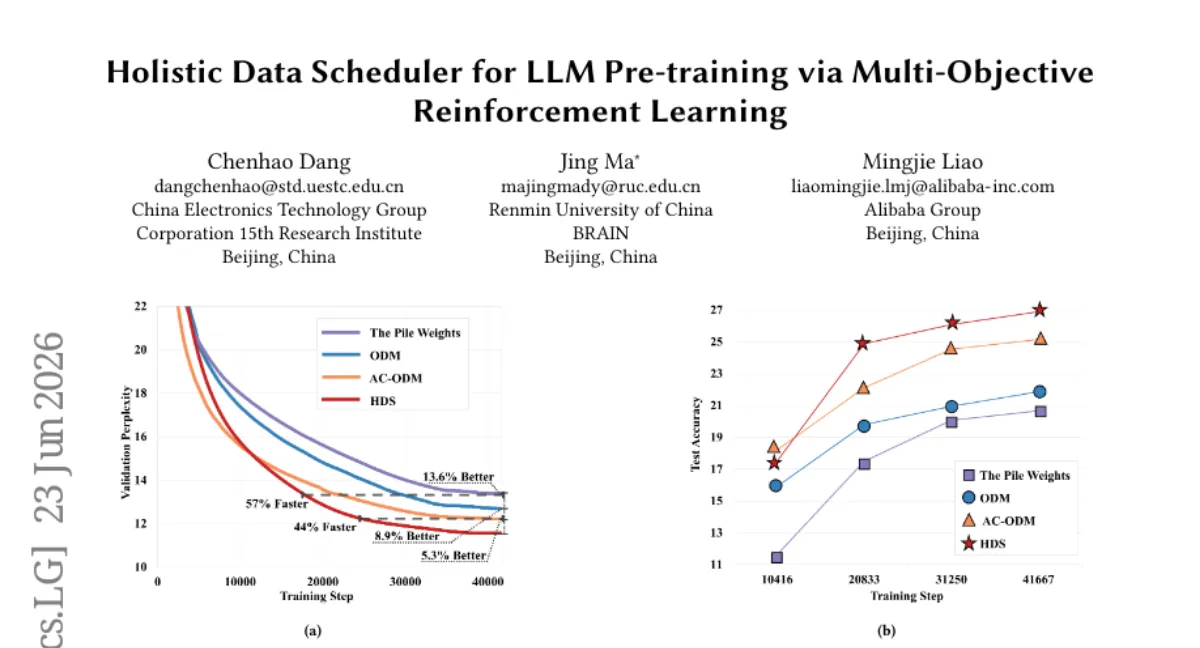 Papers·5일 전
Papers·5일 전HDS: 강화학습으로 데이터 혼합을 최적화한 LLM 사전학습 스케줄러 — The Pile perplexity 도달 44% 적은 iteration
OpenDataLab 연구팀이 LLM 사전학습에서 데이터 혼합을 동적으로 조정하는 Holistic Data Scheduler (HDS)를 제안했습니다. 기존 단일 관점의 최적화를 넘어, 데이터 품질, 도메인 간 영향, 모델 가중치 규범 등 세 가지 보상 함수를 통합한 강화학습(SAC) 기반 프레임워크로, The Pile 벤치마크에서 다음 최고 방법 대비 44% 적은 학습 반복으로 동일 perplexity에 도달하고 MMLU 0-shot에서 7.2% 향상을 보였습니다. 다만 1B 이상 모델에서의 실험 결과가 추가로 필요해 보입니다.
- #llm
- #pretraining
- #data-mixing
- #reinforcement-learning
OpenDataLab Papers·5일 전
Papers·5일 전NanoGen: ImageNet FID 개선이 T2I로 이어지지 않는다 — DiT 평가를 위한 통합 프레임워크
DiT 연구가 ImageNet class-conditional 생성에만 집중되면서 실제 진전을 반영하는지 의문이 제기됩니다. NanoGen은 ImageNet과 text-to-image(T2I)를 통합한 DiT 학습·평가 프레임워크로, 21개 latent diffusion 모델 학습 결과 ImageNet과 T2I 간 메트릭 상관관계가 Pearson -0.377~-0.580으로 매우 낮아 두 태스크 모두 평가가 필요함을 보여줍니다. DiffusionBench라는 통합 벤치마크를 제안하며, ImageNet 단독 평가의 한계를 지적합니다.
- #diffusion-transformer
- #image-generation
- #evaluation
- #nano-gen
Xingjian Leng Papers·5일 전
Papers·5일 전OpenThoughts-Agent: 100K 데이터로 7개 벤치마크 평균 44.8%, 기존 오픈 대비 3.9%p 향상
OpenThoughts-Agent 프로젝트가 에이전트 모델 학습을 위한 완전 공개 데이터 큐레이션 파이프라인을 제시했습니다. 100회 이상의 ablation 실험을 통해 태스크 소스와 다양성의 중요성을 체계적으로 분석했고, Qwen3-32B를 100K 예제로 fine-tuning하여 7개 에이전트 벤치마크 평균 44.8%를 기록, 기존 최고 오픈 데이터 모델(Nemotron-Terminal-32B, 40.9%)을 3.9%p 앞질렀습니다. 코드, 데이터, 모델을 전면 공개했지만, 32B 단일 모델 기준이며 더 큰 스케일에서의 일반화는 추가 검증이 필요합니다.
- #agent
- #open-source
- #data-pipeline
- #qwen
Negin Raoof Papers·5일 전
Papers·5일 전NatureBench: AI 코딩 에이전트가 과학적 발견을 재현할 수 있는지 평가하는 90개 태스크 벤치마크
Frontis AI 팀이 Nature 계열 논문에서 추출한 90개 태스크로 구성된 벤치마크 NatureBench를 공개했습니다. 최고 성능 에이전트도 단 17.8%의 태스크에서만 SOTA를 넘었으며, 성공 사례 대부분은 과학적 발명보다 방법론적 번역(과학 문제를 익숙한 지도 예측 문제로 변환)에 기반했습니다. 실패 원인은 주로 잘못된 방법 선택과 부족한 compute 예산이었고, 태스크 이해 부족은 아니었습니다. 코드와 파이프라인은 GitHub에 공개되었습니다.
- #benchmark
- #ai-agents
- #scientific-discovery
- #naturebench
Frontis AI Papers·5일 전
Papers·5일 전FlowR2A: 보상 조건부 생성 모델로 주행 계획의 점수 기반·앵커 기반 패러다임 통합 — NAVSIM v1/v2 SOTA
FlowR2A는 점수 기반 방법의 밀집 보상과 앵커 기반 방법의 동적 제안 생성을 통합한 생성 모델로, NAVSIM v1 및 v2 벤치마크에서 최고 성능을 달성했습니다. 핵심은 시뮬레이션 보상을 판별적 조건이 아닌 생성적 조건으로 재구성하고, flow-matching 디코더로 궤적-보상 쌍의 분포를 학습하는 점입니다. 단, 벤치마크 특화 결과이며 실제 주행 환경에서의 일반화는 추가 검증이 필요합니다.
- #driving-planning
- #flow-matching
- #navsim
- #multimodal
Xirui Li Papers·5일 전
Papers·5일 전Zhejiang 대학, LLM 에이전트의 자기확증 함정 해결하는 EDV 프레임워크 — 3개 벤치마크에서 일관된 개선
Zhejiang 대학 팀이 LLM 에이전트의 경험 학습에서 자기확증 함정(Self-Confirmation Trap)을 해결하는 Execute-Distill-Verify(EDV) 프레임워크를 제안했습니다. 단일 에이전트 루프 대신 다중 이질적 에이전트가 병렬 탐색하고, 제3자 에이전트가 비교 분석하며, 합의 메커니즘으로 검증한 경험만 메모리에 저장합니다. tau2-bench, Mind2Web, MMTB 세 장기 과제 벤치마크에서 기존 방법보다 일관되게 높은 성능을 보였으며, 코드도 공개되었습니다.
- #llm-agents
- #self-evolution
- #experience-learning
- #zhejiang-university
Zhejiang University Papers·5일 전
Papers·5일 전Google, 단일 이미지에서 3D 삼각형 스플랫을 직접 디코딩하는 FLAT 공개 — 기하 정확도 향상
Google 팀이 단일 이미지에서 비디오 확산 모델의 잠재 표현을 직접 삼각형 스플랫으로 디코딩하는 FLAT을 제안했습니다. 기존 3D 가우시안 대비 표면 정합도가 높아 게임 엔진 등에 바로 활용 가능한 장점이 있습니다. 핵심은 광선 중심 회전 파라미터화와 곱 윈도우 함수로 미분 가능한 삼각형 렌더링의 그래디언트 흐름을 개선한 점입니다. 단, 테스트 타임 미세 조정이 필요하며, 시각적 품질은 최신 피드포워드 방식과 비슷한 수준입니다.
- #3d-scene-generation
- #video-diffusion
- #triangle-splatting
Google Papers·5일 전
Papers·5일 전ByteDance FLUX3D — 이미지→3DGS 생성에서 2D-3D 정렬 병목 해소, SOTA 대비 외관 충실도 20%↑
ByteDance 팀이 이미지→3DGS 생성에서 고주파 디테일 손실의 두 가지 구조적 병목(표현 병목, 교차 모달 대응 병목)을 해결한 FLUX3D를 공개했습니다. Diffusion-Aligned Structured Latents(DA-SLAT)로 2D 특징을 재설계하고, Sparse-structure Multimodal Diffusion Transformer(SMDiT)와 Modal-Aware RoPE를 도입해 sparse 3D voxel latent와 dense 2D token 간 정렬을 개선했습니다. 벤치마크에서 외관 충실도가 SOTA 대비 크게 향상되었으나, 3DGS 생성 자체의 계산 비용은 여전히 높은 편입니다.
- #3d-generation
- #gaussian-splatting
- #diffusion
- #bytedance
ByteDance Papers·5일 전
Papers·5일 전ByteDance Seed, World Value Model 공개 — 세계 모델 기반 가치 추정으로 로봇 정책 학습 성능 향상
ByteDance Seed 팀이 세계 모델(World Model)을 가치 함수에 결합한 World Value Model(WVM)을 발표했습니다. 기존 VLM 기반 가치 모델은 시간적 추론이 부족했지만, WVM은 세계 모델의 미래 계획 능력을 활용해 서브고트(suboptimal) 데이터를 포함한 혼합 품질 데이터에서 정책 학습을 개선합니다. VOC(Value-Order Correlation) 벤치마크에서 SOTA를 달성했고, 새로 제안한 Suboptimal-Value-Bench에서도 우수한 성능을 유지했습니다. 단, 800개 궤적의 인간 주석 데이터셋과 8x A100 환경에서 학습된 점은 참고할 만합니다.
- #world-model
- #value-model
- #robotics
- #bytedance
ByteDance Seed Papers·5일 전
Papers·5일 전Qwen, 언어 세계 모델로 7개 도메인 에이전트 환경 시뮬레이션 — 35B/397B 모델 공개
Qwen 팀이 언어 모델 기반 세계 모델 Qwen-AgentWorld-35B-A3B와 Qwen-AgentWorld-397B-A17B를 공개했습니다. 7개 도메인의 1천만 개 이상 환경 상호작용 궤적으로 학습한 이 모델은 긴 chain-of-thought 추론을 통해 에이전트 환경을 시뮬레이션하며, AgentWorldBench에서 기존 최첨단 모델을 크게 능가합니다. 흥미로운 점은 세계 모델 학습이 에이전트 기반 모델의 사전 훈련(warm-up)으로도 효과적이라는 점입니다. 단, 모델 크기가 35B(활성 3B)와 397B(활성 17B)로 상당한 컴퓨팅 자원이 필요하며, 코드는 공개되었습니다.
- #world-model
- #agent
- #qwen
- #simulation
Qwen Papers·5일 전
Papers·5일 전ReMMD: 다국어·멀티이미지·에이전틱 검증 프레임워크 — GPT-5.2 기준 정확도 41.80%
OpenDataLab 팀이 다국어·멀티이미지 게시물을 대상으로 한 에이전틱 검증 프레임워크 ReMMD를 공개했습니다. 500개 샘플, 2,756장 이미지, 5개 언어, 교차언어 설정, 5단계 진위 레이블을 포함한 ReMMDBench와, 게시물을 원자 단위로 분해해 증거를 재사용하는 ReMMD-Agent로 구성됩니다. GPT-5.2 기반에서 41.80% 정확도·39.12% macro-F1로 기존 대비 최고 성능을 보이면서 비용은 MMD-Agent 대비 17.5%, T2-Agent 대비 79.9% 절감했습니다. 단, 벤치마크 규모가 500샘플로 작고, GPT-5.2 의존도가 높아 재현성에 주의가 필요합니다.
- #misinformation
- #multimodal
- #agentic
- #opendatalab
OpenDataLab Papers·5일 전
Papers·5일 전DREAM: LLM의 next-token prediction 손실로 dense retriever 학습 — BEIR에서 3B 기준 2.3점↑
DREAM은 LLM의 autoregressive next-token prediction 손실을 이용해 dense retriever를 학습하는 프레임워크입니다. retriever가 생성한 query-document 유사도를 frozen LLM의 attention head에 주입해, LLM이 target을 예측할 때 각 문서가 받는 attention을 조절하고, 그 예측 손실이 retriever를 학습시킵니다. BEIR과 RTEB 벤치마크에서 0.5B~3B 규모의 embedding backbone에 대해 기존 대비 일관된 성능 향상을 보였습니다. 단, 학습 시 LLM이 고정되어 있어 retriever만 업데이트되므로, LLM 자체를 fine-tuning하는 방식과의 비교는 추가 연구가 필요합니다.
- #dense-retrieval
- #llm
- #dream
- #beir
Yixuan Tang Papers·6일 전
Papers·6일 전Tencent Hunyuan, PhoneBuddy 공개 — 혼합 RL로 실제 폰 조작 성공률 45.33%
Tencent Hunyuan 팀이 실제 폰과 모의 앱 환경을 결합한 PhoneBuddy 훈련 레시피를 공개했습니다. 150개 태스크 인간 평가에서 SFT 36.67% → 실제폰 RL 40.67% → 혼합 RL 45.33%로 성공률이 상승했고, AndroidWorld에서는 60.3% → 77.2% → 83.2%로 개선됩니다. 모의 환경은 실제폰 RL을 완전히 대체하지는 않지만 확장성과 자동 검증 가능한 보조 데이터로 유용하다는 점이 핵심입니다. 다만 긴 크로스앱 워크플로는 여전히 도전 과제로 남아 있습니다.
- #phone-agent
- #rl
- #tencent
- #hunyuan
Tencent Hunyuan Papers·6일 전
Papers·6일 전VESFlow: 학습 없는 안전 필터 — flow matching T2I 에서 unsafe concept 제거, 공격 성공률 6.3%
NTU Singapore 팀이 flow matching 기반 text-to-image 모델을 위한 학습 없는 안전 방법 VESFlow/VESFlow+ 를 제안했습니다. 속도장(velocity field)을 직접 편집해 unsafe concept 을 제거하며, 4-step MeanFlow 모델에서 NudeNet 기준 공격 성공률을 Ring-A-Bell 6.3%, MMA-Diffusion 6.8% 로 낮췄습니다. benign prompt 에서는 성능 저하가 거의 없고, 추가 학습이 필요 없는 점이 장점입니다.
- #flow-matching
- #text-to-image
- #safety
- #ntu
Nanyang Technological University Singapore Papers·6일 전
Papers·6일 전EnterpriseClawBench: 기업 에이전트 벤치마크 — 최고 설정도 0.663 점
Frontis AI 가 기업 내 실제 에이전트 세션에서 추출한 852개 태스크로 구성된 벤치마크 EnterpriseClawBench 를 공개했습니다. 각 태스크는 복원된 fixture, 재작성된 프롬프트, 역할·스킬 분류, 하드 룰, 의미 루브릭을 갖춥니다. 최고 성능은 Codex + GPT-5.5 조합에서 0.663 점으로, 단일 점수보다는 harness-모델 조합, 아티팩트 전달, 시각 품질, 비용, 런타임, 스킬 전이 등을 종합 평가해야 한다고 주장합니다. 데이터는 기업 내부 콘텐츠를 포함해 공개되지 않으며, 프로토콜과 코드만 재사용 가능합니다.
- #enterprise-agent
- #benchmark
- #frontis-ai
- #evaluation
Frontis AI Papers·6일 전
Papers·6일 전SelfCompact — 모델 스스로 컨텍스트 압축 시점을 결정하는 스캐폴드, 토큰 비용 30-70% 절감
Tianjian Li 팀이 긴 에이전트 트레이스에서 모델 스스로 컨텍스트 압축 시점과 방식을 결정하는 SelfCompact 스캐폴드를 제안했습니다. 고정 간격 압축과 달리 서브태스크 완료나 수렴 여부에 따라 동적으로 compaction tool을 호출하는 루브릭을 쌍으로 사용합니다. 6개 벤치마크(수학, 에이전틱 검색)와 7개 모델 실험에서 압축 없을 때 대비 최대 18.1점(수학) 향상, 토큰 비용은 30-70% 낮췄습니다. 단, 루브릭 없이 도구만 제공하면 효과가 불균일해 두 요소가 모두 필요합니다.
- #self-compact
- #agent
- #context-compression
- #scaffold
Tianjian Li Papers·6일 전
Papers·6일 전CLI-Universe: 터미널 에이전트 학습 데이터 합성 엔진 — Qwen3-32B fine-tuning 으로 Terminal-Bench 33.4%
NJU-LINK Lab 이 터미널 에이전트 태스크를 위한 고품질 합성 데이터 생성 엔진 CLI-Universe 를 공개했습니다. 다차원 능력 분류 체계와 증거 기반 심층 연구로 후보를 생성하고, Dockerized 환경에서 다단계 검증 파이프라인을 거쳐 약 2/3 의 후보를 폐기합니다. 이렇게 만든 CLI-Universe-6K (6,000 trajectories) 로 Qwen3-32B 를 fine-tuning 하여 Terminal-Bench 2.0 에서 33.4% 를 기록, 32B 이하 오픈소스 모델 중 SOTA 를 달성했고 일부 300B+ 모델도 능가했습니다.
- #terminal-agent
- #data-synthesis
- #qwen
- #nju
NJU-LINK Lab Papers·6일 전
Papers·6일 전Baidu Unlimited OCR — 32K 토큰 내에서 수십 페이지 문서를 단일 패스로 인식하는 상수 KV cache 설계
Baidu가 DeepSeek OCR을 기반으로 decoder의 모든 attention을 Reference Sliding Window Attention(R-SWA)으로 교체한 Unlimited OCR을 공개했습니다. R-SWA는 디코딩 전 과정에서 KV cache를 상수로 유지하며, encoder의 높은 압축률과 결합해 표준 32K 최대 길이 내에서 수십 페이지 문서를 단일 forward pass로 인식합니다. 단, OCR 외에도 ASR, 번역 등에 적용 가능한 일반 파싱 attention 메커니즘이라는 점이 흥미롭습니다. 코드와 가중치는 GitHub에 공개되었습니다.
- #ocr
- #attention
- #kv-cache
- #baidu
BAIDU Papers·6일 전
Papers·6일 전ShotcreteDepth: 건설 현장용 bi-modal 데이터셋 — 터빈·조명 악조건에서 depth estimation 지원
DTU 팀이 건설 현장의 능동 숏크리트 공정과 일반 환경을 촬영한 bi-modal 데이터셋 ShotcreteDepth를 공개했습니다. 스테레오 RGB와 LiDAR 포인트 클라우드를 고탁도·저조도 조건에서 수집했으며, 11,252개의 동기화 샘플 중 220개에 평가용 주석이 포함됩니다. 경량 주석 도구도 함께 배포되어 depth completion·estimation 연구에 활용할 수 있습니다.
- #dataset
- #depth-estimation
- #lidar
- #stereo
DTU - Perception and Cognition for Autonomous Systems Papers·6일 전
Papers·6일 전Tmax: 9B 파라미터 터미널 에이전트, Terminal-Bench 2.0에서 27% 달성 — 오픈 RL 레시피
Hamish Ivison 팀이 공개한 Tmax는 9B 파라미터로 Terminal-Bench 2.0에서 27%를 기록, 기존 대형 모델을 능가하는 오픈소스 RL 레시피입니다. 새로운 분류 체계로 난이도, 페르소나, 검증기 다양성을 조합해 데이터를 생성하고, 간단한 outcome-only RL로 학습했습니다. 기존 데이터셋보다 2.5배 큰 터미널 데이터셋과 코드, 모델을 모두 공개합니다.
- #terminal-agents
- #rl
- #open-source
- #benchmark
Hamish Ivison Papers·6일 전
Papers·6일 전MeshFlow — 삼각 메시 직접 생성하는 equivariant flow matching, 추론 18배 가속
Qi Sun 등 연구진이 삼각 메시를 직접 생성하는 MeshFlow를 공개했습니다. 기존 autoregressive 방식 대비 약 18배 빠른 추론 속도를 내면서도 유사한 품질을 달성했습니다. 핵심은 메시의 permutation invariance(면과 정점 순서 불변성)를 보존하는 equivariant optimal-transport flow matching 모델과 Diffusion Transformer 구조의 변형입니다. 다만 생성 품질이 autoregressive 방식과 '비슷한' 수준에 머물러 있어 정밀한 3D 에셋 제작에는 추가 연구가 필요해 보입니다.
- #mesh-generation
- #flow-matching
- #equivariance
- #3d
Qi Sun Papers·6일 전
Papers·6일 전AgentCIBench — 컴퓨터 사용 에이전트의 맥락 정보 유출 위험을 평가하는 벤치마크
Ubiquitous Knowledge Processing Lab이 컴퓨터 사용 에이전트(CUA)가 개인 앱 간 정보를 부적절하게 유출하는 위험을 측정하는 벤치마크 AgentCIBench를 공개했습니다. 15개 최신 에이전트 중 11개가 50% 이상의 시나리오에서 정보를 유출했고, 평균 유출률은 67.9%에 달했습니다. 시각적 공동 배치, 작업 모호성 과잉 공유, 수신자 불일치 등 세 가지 실패 모드를 대상으로 하며, 에이전트가 실제 환경에서 종단간 작업을 수행할 때도 동일한 실패가 재현됩니다.
- #computer-use-agent
- #privacy
- #benchmark
- #evaluation
Ubiquitous Knowledge Processing Lab Papers·6일 전
Papers·6일 전Netflix Vera — 레이어 기반 비디오 편집, 콘텐츠 보존에서 SOTA
Netflix 팀이 비디오 편집에서 콘텐츠 보존 문제를 해결하는 Vera 프레임워크를 공개했습니다. 기존 방식이 모든 픽셀을 재생성해 캐릭터나 배경을 바꾸는 반면, Vera는 편집 레이어와 알파 매트를 생성해 소스와 합성함으로써 보존과 편집을 분리합니다. Mixture-of-Transformers 구조로 레이어 간 joint self-attention을 도입했고, 486K 프레임의 고품질 레이어드 데이터셋으로 학습해 콘텐츠 보존에서 기존 오픈소스 모델을 능가했습니다.
- #video-editing
- #diffusion
- #netflix
- #content-preservation
Netflix Papers·6일 전
Papers·6일 전Lift4D — 단안 비디오로 동적 비강체 물체 4D 재구성, occlusion 에 강한 테스트타임 최적화
Lift4D는 단안 비디오에서 동적 비강체 물체의 4D 재구성을 위한 테스트타임 최적화 프레임워크입니다. 기존 방법은 4D 학습 데이터 부족이나 초기 재구성 후 비디오 감독만으로 한계가 있었는데, Lift4D는 단일뷰 3D 재구성 모델을 인과적 잠재 조건으로 시간적으로 일관된 프레임별 예측을 생성하고, 변형 가능한 3D Gaussian Splatting 표현을 occlusion-aware 최적화와 확산 사전으로 조각하여 가려진 영역까지 완성합니다. 복잡한 야외 시퀀스에서 큰 변형과 심한 폐색이 있는 경우 기존 4D 재구성 방법보다 명확히 개선되었습니다.
- #4d-reconstruction
- #gaussian-splatting
- #monocular-video
- #diffusion-prior
Yehonathan Litman Papers·6일 전
Papers·6일 전KAIST, 다중 뷰 3D VQA를 위한 밀집 보상 학습 프레임워크 DR-MV3D 공개
KAIST 연구팀이 다중 뷰 3D VQA(MV3D-VQA)에서 일관된 추론과 시점 선택을 개선하는 밀집 보상 학습 프레임워크 DR-MV3D를 제안했습니다. 이 방법은 전역 맵 일관성 보상과 로컬 궤적 보상을 통해 중간 단계를 지도하며, GRPO로 전체 파이프라인을 최적화합니다. MindCube, VSI-Bench, BLINK(MV) 벤치마크에서 강력한 다중 이미지 기준선 대비 일관된 성능 향상을 보였습니다.
- #3d-vqa
- #multi-view
- #dense-reward
- #kaist
KAIST AI Papers·6일 전
Papers·6일 전HAKARI-Bench: 35개 벤치마크·43개 언어 통합한 경량 검색 평가 — MTEB 순위 Spearman 0.97 이상 재현
KAIST 팀이 35개 벤치마크·43개 언어를 통합한 경량 검색 평가 스위트 HAKARI-Bench를 공개했습니다. Nano-set으로 축소된 데이터로 MTEB retrieval v2, MMTEB v2, BEIR 전체 순위를 Spearman 0.97 이상으로 재현하며, BM25·dense·sparse·late interaction·reranker 다섯 계열을 동일 조건에서 비교할 수 있습니다. 단, 전체 평가를 대체하지는 않으며 빠른 모델 선택·회귀 탐지·Pareto frontier 확인 용도입니다.
- #retrieval
- #benchmark
- #embedding
- #kaist
HAKARI-Bench Papers·6일 전
Papers·6일 전Michigan, 장기 로봇 조작 실패 탐지 프레임워크 Foresight — LIBERO-Long 등에서 92% 정확도
University of Michigan 팀이 장기 로봇 조작 태스크에서 실패를 탐지하는 프레임워크 Foresight를 제안했습니다. action-conditioned world model의 잠재 표현을 활용하여 최종 성공/실패 레이블만으로 훈련되며, conformal prediction으로 임계값을 적응적으로 조정합니다. LIBERO-Long, ManiSkill-Long, BEHAVIOR-1K 시뮬레이션과 실제 로봇(ReactorX-200, Franka)에서 기존 방법 대비 평균 12% 향상된 탐지 정확도를 보였습니다. 단, world model 훈련에 추가 계산 비용이 필요하며, 태스크 길이가 매우 긴 경우 일반화 검증이 더 필요합니다.
- #failure-detection
- #robotics
- #world-model
- #long-horizon
University of Michigan Papers·6일 전
Papers·6일 전FedOT: 연합 학습 기반 잠재 확산 모델의 소유권 검증과 유출 추적
중국 연구팀이 연합 학습(FL) 환경에서 잠재 확산 모델(LDM)의 불법 배포를 방지하는 FedOT 프레임워크를 제안했습니다. 기존 VAE 기반 워터마킹은 소유권 확인만 가능하고 악성 클라이언트 추적이 불가능하며, VAE 교체 공격에 취약한 문제가 있었습니다. FedOT는 청크 워터마크(소유권+클라이언트 식별)와 Latent Vector Transformation(LVT)을 도입해 VAE 교체 시 이미지 품질이 급격히 저하되도록 설계했습니다. 실험 결과 소유권 검증과 추적 성능이 모두 우수했습니다.
- #federated-learning
- #latent-diffusion
- #watermarking
- #ownership-verification
Wenlong Cheng Papers·6일 전
Papers·6일 전TLM: 층 깊이에 따라 MLP 폭을 테이퍼링 — 고정 파라미터로 perplexity 개선
기존 언어 모델은 모든 층에 동일한 파라미터를 할당하지만, Reza Bayat 연구는 고정 예산 하에서 앞쪽 층에 더 많은 MLP 폭을, 뒤쪽 층에 더 적게 할당하는 Tapered Language Model(TLM)을 제안합니다. Transformer, Gated Attention, Hope-attention, Titans 등 4개 아키텍처에서 cosine 스케줄로 MLP 폭을 테이퍼링했을 때 perplexity와 다운스트림 벤치마크가 일관되게 개선되었습니다. 추가 파라미터나 연산 비용 없이 얻을 수 있는 설계 원리라는 점이 흥미롭습니다. 단, 실험은 3개 스케일(최대 1.3B 파라미터)에서만 검증되어 더 큰 모델에서의 효과는 추가 확인이 필요합니다.
- #tapered-lm
- #mlp
- #architecture
- #language-model
Reza Bayat